Sliding Time Window Aggregator*¶
支持对单个测点的数据按时间窗口聚合,具体功能如下:
窗口类型:支持滑动窗口
聚合算法:支持 max/min/avg/count/sum/first/last
因任何原因导致的失败重试,比如集群节点异常,不能保证计算结果幂等。
与旧数据格式不兼容,即无法按
ModelId::PointId进行数据过滤
配置详情¶
该算子的配置包括 General,Basic,Input/Output,ExtraConfig,和 CacheConfig 的详细信息,各字段的配置如下:
General¶
名称 |
是否必须 |
描述 |
|---|---|---|
Name |
Yes |
算子名称 |
Description |
No |
算子描述 |
Stage Library |
Yes |
算子所属的库 |
Required Fields |
No |
数据必须包含的字段,如果未包含指定字段,则 record 将被过滤掉 |
Preconditions |
No |
数据必须满足的前提条件,如果不满足指定条件,则 record 将被过滤掉。例如: |
On Record Error |
Yes |
对错误数据的处理方式,可选:
|
Basic¶
名称 |
是否必须 |
描述 |
|---|---|---|
Quality Filter |
No |
根据数据质量过滤处理数据,只有符合质量条件的 record 才会进行此次处理 |
Input/Output¶
名称 |
是否必须 |
描述 |
|---|---|---|
Input Measurement |
Yes |
数据输入点 |
Fixed Window Size |
Yes |
固定窗口的步长 |
Fixed Window Unit |
Yes |
固定窗口的时间单位 |
Sliding Window Size |
Yes |
滑动窗口的步长 |
Sliding Window Unit |
Yes |
滑动窗口的时间单位 |
Aggregator Policy |
Yes |
数据聚合算法,支持 max/min/avg/count/sum/first/last |
Output Measurement |
Yes |
数据输出点 |
ExtraConfig¶
名称 |
是否必须 |
描述 |
|---|---|---|
Output Data Type |
Yes |
选择输出数据的类型,可选 Double 或 From Catalog Service:
|
CacheConfig¶
名称 |
是否必须 |
描述 |
|---|---|---|
Cache Type |
Yes |
选择缓存数据的类型,可选 Redis 存储或 Local 存储。
|
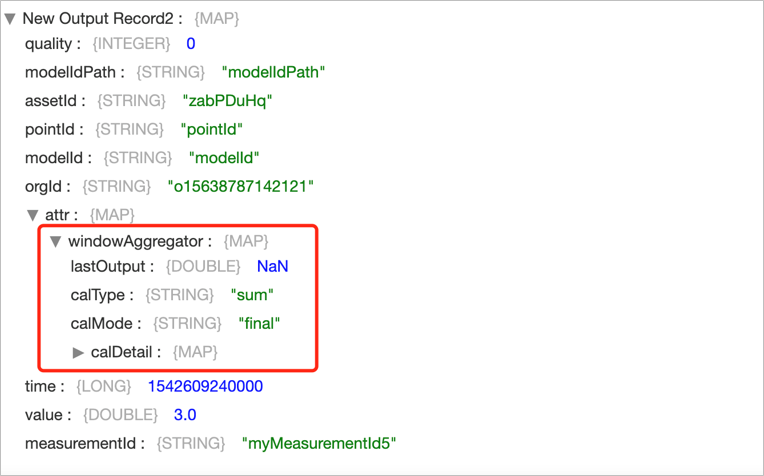
输出结果¶
该算子的输出结果包含在 attr 结构体中,各字段的描述如下:
名称 |
数据类型 |
描述 |
|---|---|---|
lastOutput |
Int/Double/Float |
该测点在该 timestamp,上一次输出的值;上一次无输出则为 NaN |
calMode |
String |
输出模式:输出最终结果 “final” |
calType |
String |
聚合算法:max/min/avg/count/sum/first/last |
calDetail |
Map |
计算详情:该如 calType=avg 时,输出 value&lastValue 的 sum 和 count 信息 |
备注
该算子的输出结果中 modelIdPath, pointId, modelId 三个 key 所对应的 value 都是默认字符串,分别为: modelIdPath, pointId, modelId。
输出示例¶