入门指引¶
资源准备
配置和运行流数据处理任务前,需确保组织已经通过 EnOS 管理控制台 > 资源管理 页面申请 流数据处理 资源。流数据处理 资源包含以下几种资源模式,分别用于开发和运行流数据处理任务:
设计态资源:用于安装流数据处理算法模板、系统算子包、或自定义算子包,创建和设计流数据处理任务。
Standalone模式:用于以 Standalone 模式运行流数据处理任务。
集群模式:用于以集群模式运行流数据处理任务。
有关申请 流数据处理 资源的详细信息,参见 流数据处理资源规格说明。
当业务不再需要运行流数据处理任务,可通过 资源管理 页面删除和释放已申请的流数据处理资源,降低资源使用成本。
安装算法模板和算子包
开发流数据处理任务之前,需要安装对应的算法模板和算子包。
前提条件¶
已被授权使用流数据处理服务
组织已申请流式计算资源下的流数据处理-设计态资源。更多信息,参见 资源准备。
安装算法模板
通过以下步骤安装算法模板:
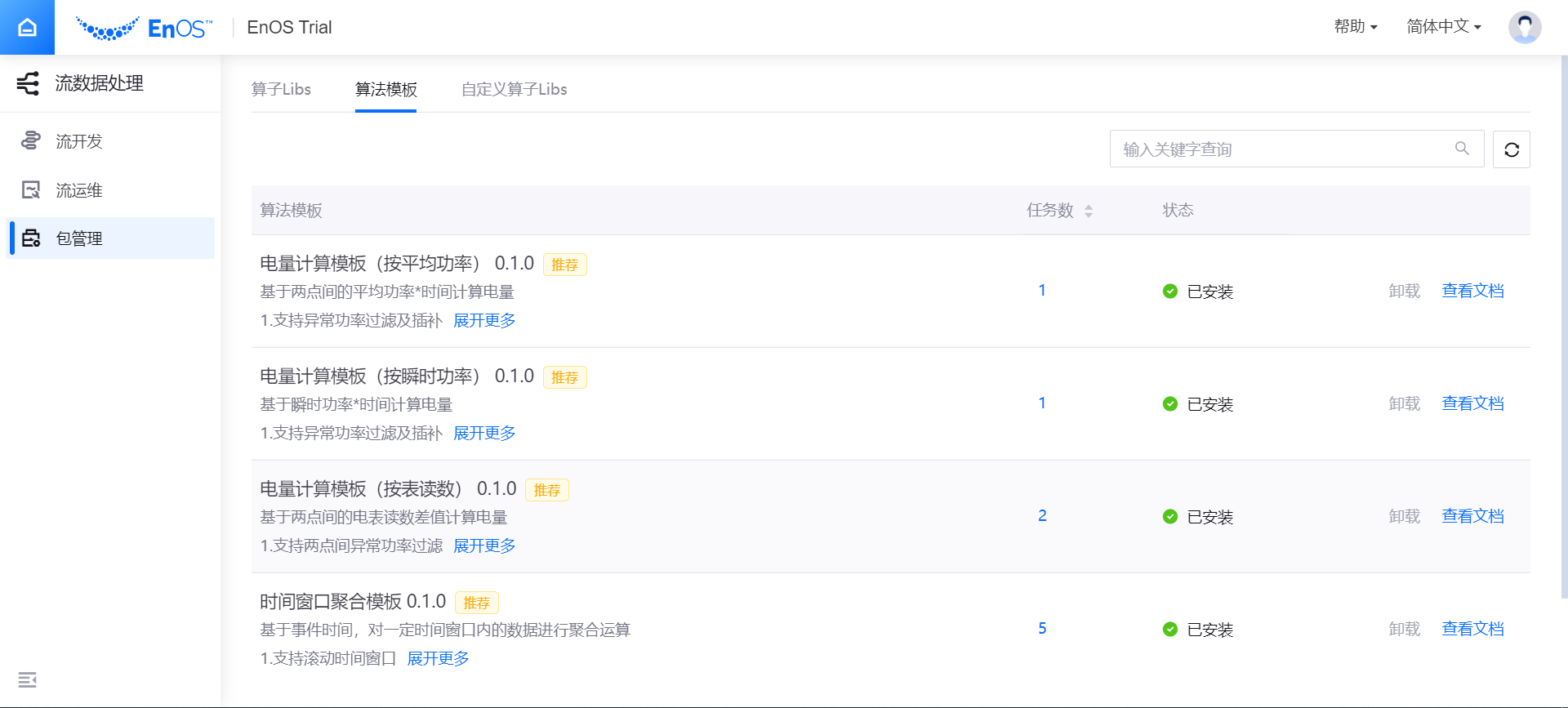
登录 EnOS 管理控制台,在 企业数据平台 分类下选择 流数据处理 > 包管理。
点击 算法模板 标签,查看可安装的算法模板。目前支持安装以下算法模板:
时间窗口聚合模板:支持对单设备单测点数值类型数据的聚合处理
电量计算模板(按表读数):支持按电能表读数计算天级电量
电量计算模板(按瞬时功率):支持按瞬时功率计算天级电量
电量计算模板(按平均功率):支持按平均功率计算天级电量
确定需要安装的算法模板后,点击 安装,系统会自动开始安装算法模板。
安装系统算子包¶
通过以下步骤安装系统算子库:
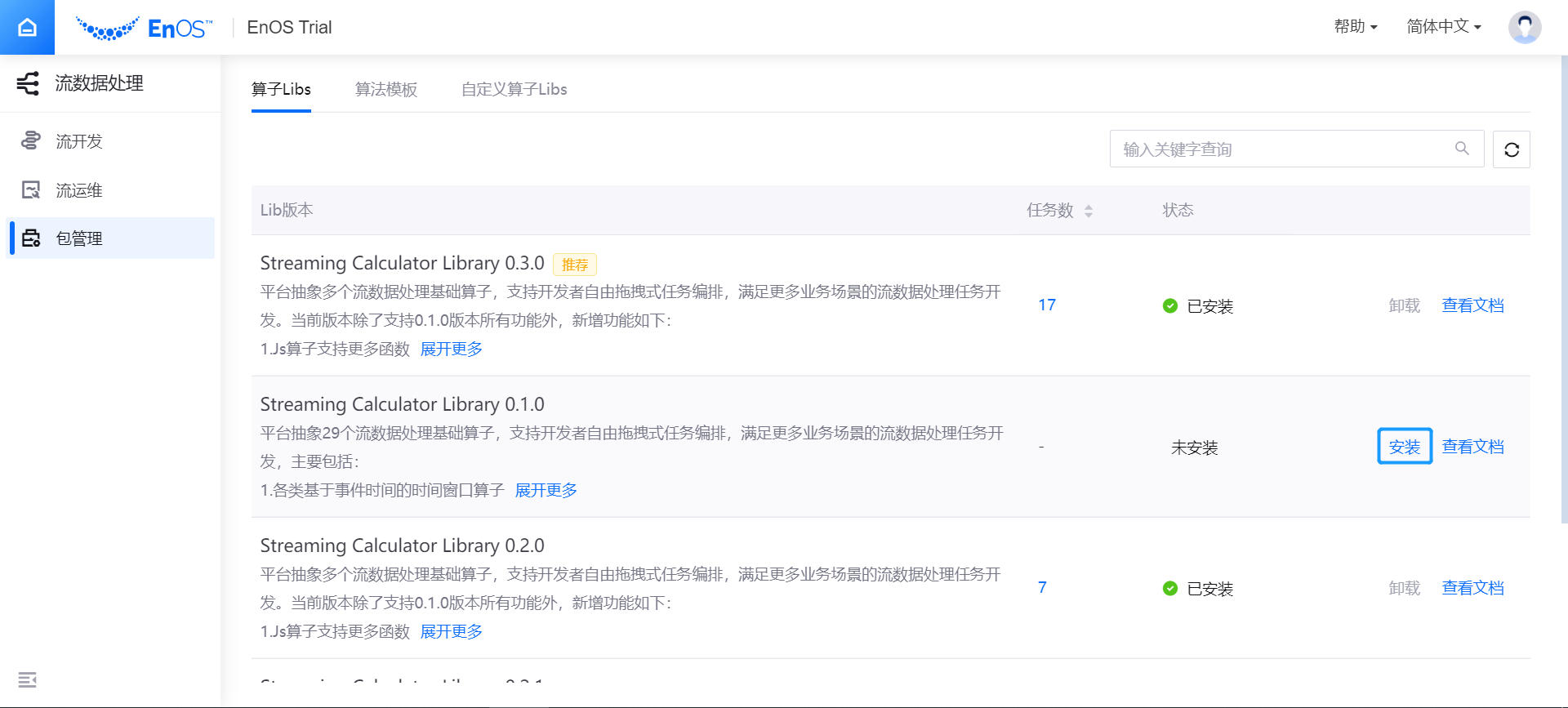
登录 EnOS 管理控制台,在 企业数据平台 分类下选择 流数据处理 > 包管理。
在 算子Libs 标签下,查看可安装的算子库。
确定需要安装的算子包后,点击 安装,系统会自动开始安装算子包。
安装自定义算子包¶
登录 EnOS 管理控制台,在 企业数据平台 分类下选择 流数据处理 > 包管理。
在 自定义算子Libs 标签下,点击 添加算子lib,上传和安装自定义算子包。
分别输入算子包的名称、版本、和描述(算子包名称可重复,但算子包版本需高于已有算子包的版本)。
上传算子包文件(需封装为 .tar.gz 文件格式,且不能超过300M)。
上传元数据文件(需封装为 .zip 文件格式,且不能超过5M)。
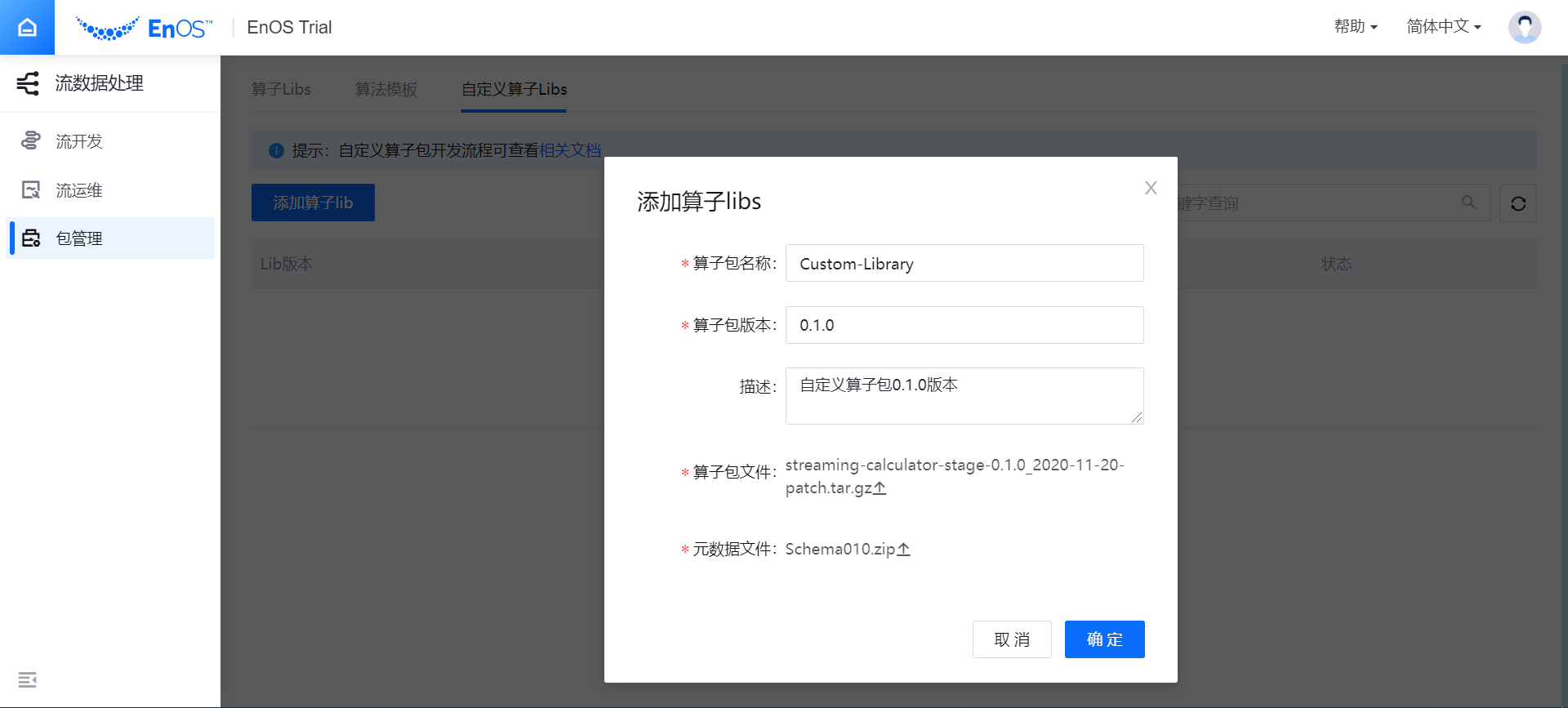
点击 确定,系统会开始上传算子包文件和元数据文件。上传完成后,算子包将会显示在自定义算子包列表中,其状态为 未安装。
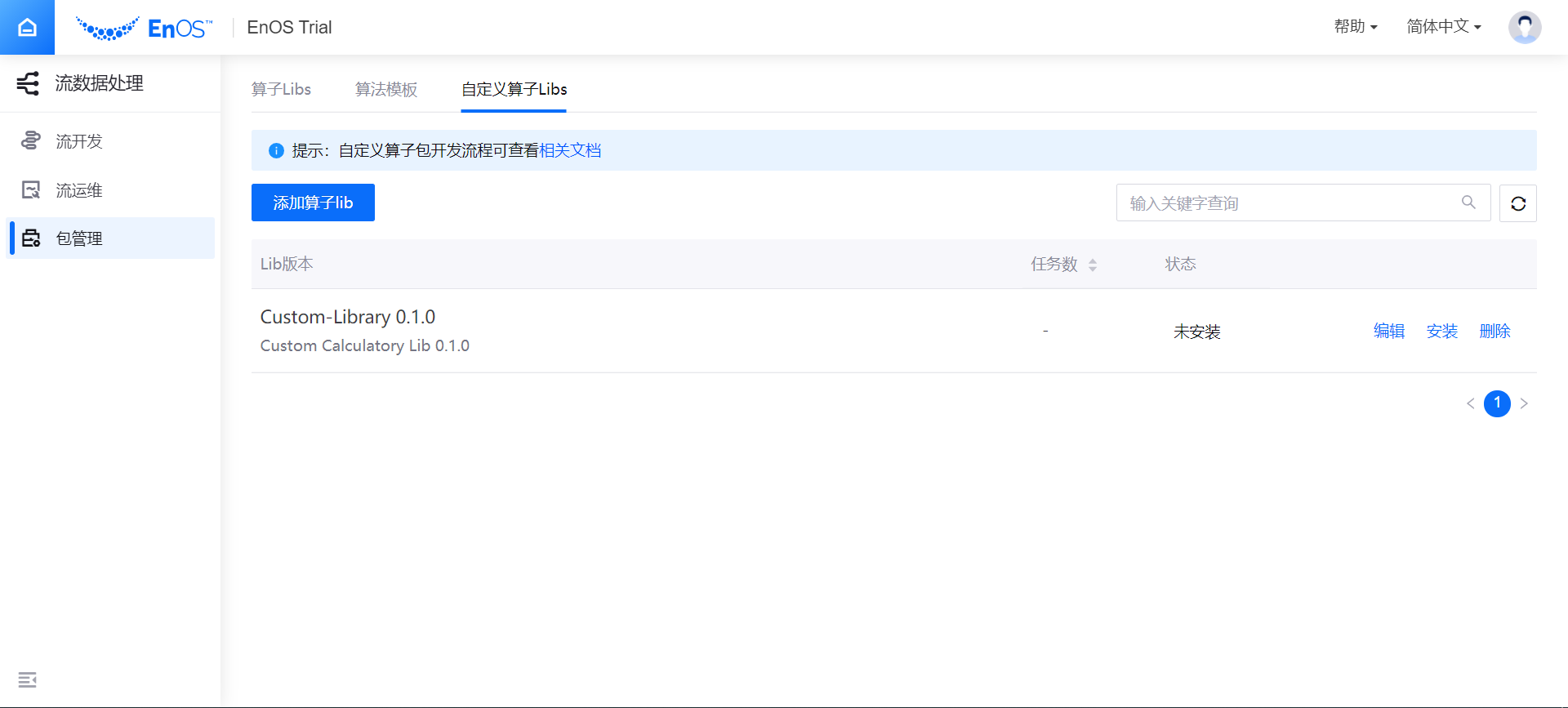
点击 安装,系统会自动开始安装自定义算子包。
卸载算法模板或算子包¶
如业务不再需要已安装的算法模板、系统算子包、或自定算子包,可将其卸载,释放设计态资源。
备注
卸载算法模板或算子库之前,必须确保模板或算子库已无相关联的流数据处理任务。
数值型数据聚合处理教程¶
本教程能帮助你快速学习如何使用 时间窗口聚合模板 对数值类型流数据进行聚合处理。
前提条件¶
操作步骤¶
使用 时间窗口聚合模板 进行数值类型流数据处理的步骤如下:
使用模板创建并配置流数据处理任务
保存并发布任务
配置任务运行资源
启动任务
查看任务运行结果
教程目标及数据准备¶
教程目标
本教程要实现的场景是:将原始采集点 test_raw 的数据进行每5分钟取最大值,取值结果输出给新点 test_5min。
数据准备
模型配置:本教程使用的模型 (test_Model) 配置如下:
功能类型 |
名称 |
标识符 |
测点类型 |
数据类型 |
|---|---|---|---|---|
测点 |
test_raw |
test_raw |
AI |
DOUBLE |
测点 |
test_5min |
test_5min |
AI |
DOUBLE |
备注
其中 test_raw 为原始数据采集点,test_5min 是原始点要经过流数据处理聚合后输出的数据点名称。
必须保证需要处理的输入点和输出点的测点类型相同。
第一步:创建并配置流数据处理任务¶
登录 EnOS 管理控制台,点击 流数据处理 > 流开发 菜单可浏览当前组织所有已创建的流数据处理任务。双击某一任务,可进行详情查看并编辑。
在任务列表上方,点击 + 添加新任务。选择常规流类型、新建流数据处理任务,并输入任务的名称和描述。
从 模板 下拉菜单中,选择已安装的 时间窗口聚合模板 和对应的模板版本号。
选择 实时通道 为数据通道,用于处理资产实时数据,然后点击 确认。
配置流数据处理任务窗口策略
窗口类型,选择滚动窗口:表示按固定的时间窗口对数据做聚合运算,窗口连续且不重叠。
延迟设置,选择:0 second 表示窗口不延迟,超出时间窗口到达的数据不被加入计算。
配置数据处理策略。点击 新增策略,列表会新增一条记录。记录的配置项描述如下:
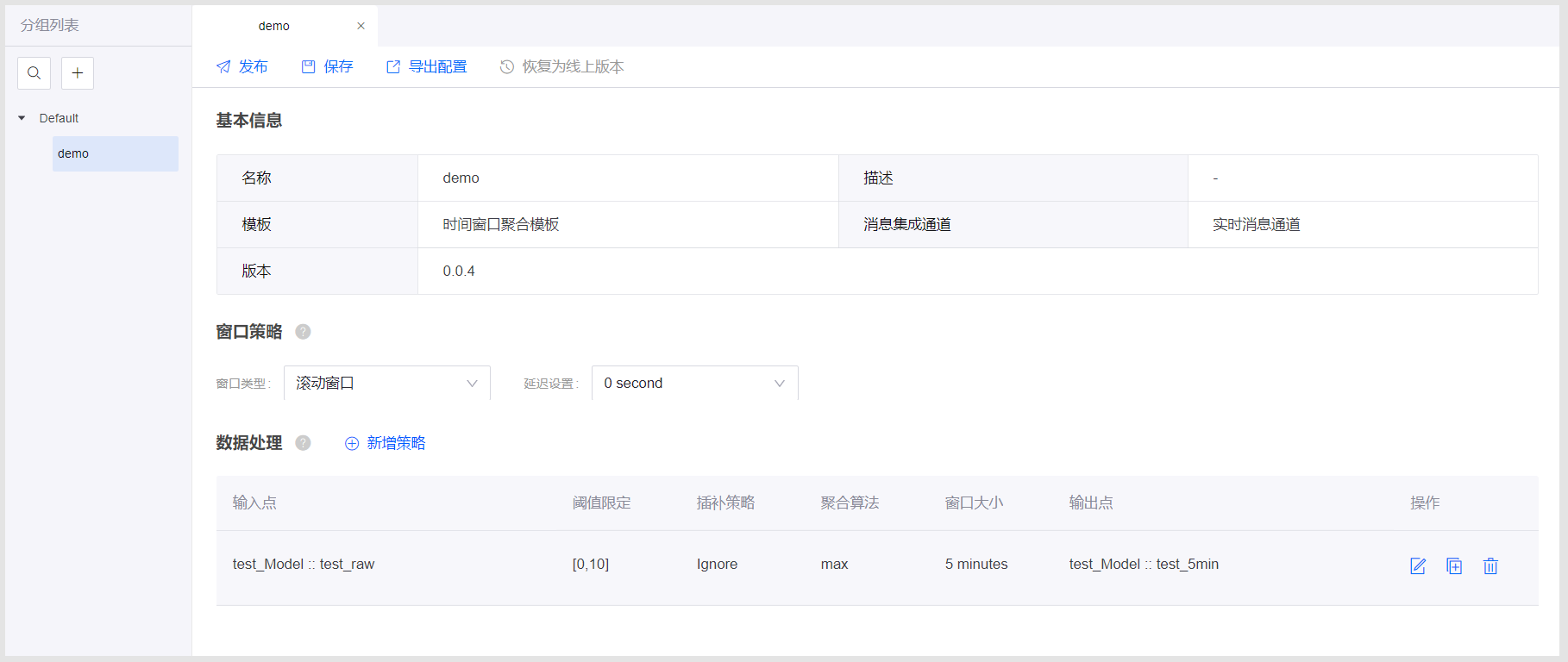
输入点:选择AI原始数据采集点,本教程中选择 test_Model的test_raw 测点
阈值限定:对参与计算的数据点进行阈值过滤,本教程设置为 [0,10]
插补策略:对超出阈值范围的数据进行插补,目前只能选择 Ignore,即超出阈值范围的数据不参与聚合计算
聚合算法:设定数据处理算法,当某一时间窗口在销毁时,会对已到达的该窗口的数据进行处理,本教程选择 max 算法
窗口大小:设定聚合算法作用的时间区间,本教程中选择 5 minutes
输出点:选择聚合结果输出点,本教程中选择 test_5min
点击 操作 列中的 保存 图标,保存数据处理策略
第二步:保存并发布流数据处理任务¶
任务配置完成后,需要对配置进行保存,保存后可激活发布按钮。点击 发布,将任务发布上线。下图为任务配置示例:
第三步:配置流数据处理任务运行资源¶
进入 流数据处理 > 流运维 页面,查看已发布的流数据处理任务,其默认状态为 PUBLISHED。在启动流数据处理任务前,需要配置流数据处理任务所需的运行资源。
通过以下步骤,配置流数据处理任务运行资源:
从 操作 列中,选择 … > 运行配置。
在弹窗中,选择 Standalone模式 作为运行模式,输入数据读取速率,然后输入运行任务所需的CU数。
点击 确定 完成运行资源配置。
备注
配置流数据处理任务运行资源,需确保组织已申请相应模式的运行资源。如需申请计算资源,请参考 快速申请资源。
第四步:启动流数据处理任务¶
为保证流数据处理任务能够正常运行,需要先启动相关的系统流任务。本教程需启动 Data Reader RealTime 系统流任务。
通过以下步骤,启动流数据处理任务:
在 流运维 页面,点击 系统流任务列表 标签,启动对应运行模式的系统流任务。
点击 用户流任务列表 标签,启动已发布的流数据处理任务。
第五步:查看任务运行结果¶
流数据处理任务启动后,在任务列表的 名称 一栏中,点击已启动的流数据处理任务名称,可查看任务运行情况:
Summary: 查看任务运行情况总结,比如整体处理记录统计、各个时间段聚合情况。
Log: 点击页面右上角 View Logs 图标,可查看任务运行日志。
Results: 可通过接口 Get Asset AI Data with Aggregation Logic 来获取输出点 test_5min 的分钟级归一化数据。调用用Open API的代码示例,请前往 EnOS 管理控制台 > EnOS API,查看API文档。