Python Evaluator*¶
支持运行原生的 Python 脚本,实现自定义的业务逻辑。与旧数据格式不兼容,即无法按 ModelId::PointId 进行数据过滤。
配置详情¶
该算子的配置包括 General,Basic,Input/Output,和 Script 的详细信息,各字段的配置如下:
General¶
名称 |
是否必须 |
描述 |
|---|---|---|
Name |
Yes |
算子名称 |
Description |
No |
算子描述 |
Stage Library |
Yes |
算子所属的库 |
Required Fields |
No |
数据必须包含的字段,如果未包含指定字段,则 record 将被过滤掉 |
Preconditions |
No |
数据必须满足的前提条件,如果不满足指定条件,则 record 将被过滤掉。例如: |
On Record Error |
Yes |
对错误数据的处理方式,可选:
|
Basic¶
名称 |
是否必须 |
描述 |
|---|---|---|
Lineage Mapping |
Yes |
选择数据输入点和数据输出点的血缘对应关系。可选:
|
Quality Filter |
No |
根据数据质量过滤处理数据,只有符合质量条件的 record 才会进行此次处理 |
Input/Output¶
名称 |
是否必须 |
描述 |
|---|---|---|
Input Measurement |
Yes |
数据输入点,输入数据的 MeasurementId 必须匹配输入点,才能够进入后续计算。 |
Output Measurement |
No |
数据输出点,经过 Python Script 脚本后的输出数据的 MeasurementId 必须匹配输出点,才能够作为真正的输出 record。 |
Script¶
名称 |
是否必须 |
描述 |
|---|---|---|
Python Script |
Yes |
编写自定义 Python 脚本。其中 records 代表所有经过选中的点并经过质量控制后,流入的数据。 |
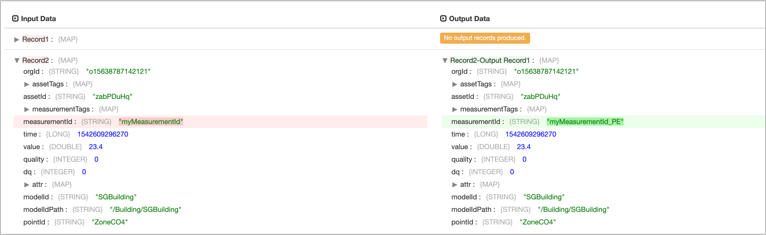
输出结果¶
运行自定义 Python 脚本后,该算子的输出结果包含在 attr 结构体中。
输出示例¶
Python 脚本开发指南¶
# Available constants:
They are to assign a type to a field with a value null.
NULL_BOOLEAN, NULL_CHAR, NULL_BYTE, NULL_SHORT, NULL_INTEGER, NULL_LONG
NULL_FLOATNULL_DOUBLE, NULL_DATE, NULL_DATETIME, NULL_TIME, NULL_DECIMAL
NULL_BYTE_ARRAY, NULL_STRING, NULL_LIST, NULL_MAP
# Available Objects:
records: an array of records to process, depending on Jython processor processing mode it may have 1 record or all the records in the batch.
state: a dict that is preserved between invocations of this script. Useful for caching bits of data e.g. counters.
log.<loglevel>(msg, obj...):
use instead of print to send log messages to the log4j log instead of stdout.
loglevel is any log4j level: e.g. info, error, warn, trace.
output.write(record): writes a record to processor output
error.write(record, message): sends a record to error
sdcFunctions.getFieldNull(Record, 'field path'): Receive a constant defined above to check if the field is typed field with value null
sdcFunctions.createRecord(String recordId): Creates a new record.
Pass a recordId to uniquely identify the record and include enough information to track down the record source.
sdcFunctions.createMap(boolean listMap): Create a map for use as a field in a record.
Pass True to this function to create a list map (ordered map)
sdcFunctions.createEvent(String type, int version): Creates a new event.
Create new empty event with standard headers.
sdcFunctions.toEvent(Record): Send event to event stream
Only events created with sdcFunctions.createEvent are supported.
sdcFunctions.isPreview(): Determine if pipeline is in preview mode.
Available Record Header Variables:
record.attributes: a map of record header attributes.
record.<header name>: get the value of 'header name'.
# Add additional module search paths:
import sys
sys.path.append('/some/other/dir/to/search')
for record in records:
try:
# write record to processor output
output.write(record)
except Exception as e:
# trace the exception
import sys
error.trace(sys.exc_info())
# Send record to error
error.write(record, str(e))