Latest Record Merger*
支持根据表达式生成分组标签,对多组输入的所有测点,根据标签进行分组后输出。对于每一分组,当该组内指定的触发点到达时,触发该组数据输出。该算子的计算逻辑如下:
- 支持输入多个测点,支持多个输入点作为计算触发点。
- 支持输出多个测点,输入点的 measurementId 会被替换成对应的输出 measurementId。
- 因任何原因导致的失败重试,比如集群节点异常,不能保证计算结果幂等。
- 与旧数据格式不兼容,即无法按
ModelId::PointId 进行数据过滤。
配置详情
该算子的配置包括 General,Basic,Input/Output,MergerConfig,和 CacheConfig 的详细信息,各字段的配置如下:
General
| 名称 |
是否必须 |
描述 |
|---|
| Name |
Yes |
算子名称 |
| Description |
No |
算子描述 |
| Stage Library |
Yes |
算子所属的库 |
| Required Fields |
No |
数据必须包含的字段,如果未包含指定字段,则 record 将被过滤掉 |
| Preconditions |
No |
数据必须满足的前提条件,如果不满足指定条件,则 record 将被过滤掉。例如:${record:value('/value') > 0}。有关 EL 语句的使用方法,参考 Expression Language。 |
| On Record Error |
Yes |
对错误数据的处理方式,可选:
- Discard:直接丢弃
- Send to Error:发送至错误中心
- Stop Pipeline:停止流任务运行
|
Basic
| 名称 |
是否必须 |
描述 |
|---|
| Quality Filter |
No |
根据数据质量过滤处理数据,只有符合质量条件的 record 才会进行此次处理 |
MergerConfig
| 名称 |
是否必须 |
描述 |
|---|
| Merged By Expression |
Yes |
生成分组标签的表达式。如果该表达式包含时间戳等其他标识信息可能会产生大量数据,在选择使用 Redis 作为数据存储时需评估对数据存储的影响并准备相应的预案。 |
| Cache Expire Time (Minute) |
Yes |
输入分组标签不再更新后的缓存失效时间 |
CacheConfig
| 名称 |
是否必须 |
描述 |
|---|
| Cache Type |
Yes |
选择缓存数据的类型,可选 Redis 存储或 Local 存储。
- Redis:优点是任务暂停、重启、或重试后,缓存数据不会丢失;缺点是数据处理速度慢,对网络比较敏感。建议网络延迟小于 1ms,否则会影响处理性能。
- Local:优点是数据处理速度快;缺点是任务暂停、重启、或重试时,缓存数据会丢失。
|
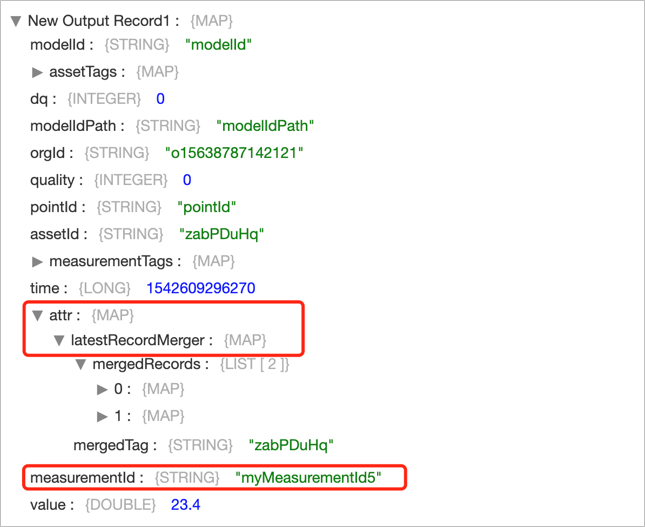
输出结果
该算子的输出结果包含在 attr 结构体中,各字段的描述如下:
| 名称 |
数据类型 |
描述 |
| /attr/latestRecordMerger |
Map |
聚合后的数据对象 |
| mergedTag |
String |
根据表达式生成的标签 |
| mergedRecords |
List |
分组聚合后的输出数据列表 |
注解
该算子的输出结果中 modelIdPath, pointId, modelId 三个 key 所对应的 value 都是默认字符串,分别为: modelIdPath, pointId, modelId。
输出示例