S3 File¶
The S3 File node automatically scans a specified bucket and downloads a single file or multiple files from an AWS S3 server according to the interval and the URI. Nodes under the Action node type such as the File node can subsequently be used to read/write to the file.
If you only need to download a single S3 file once, it is recommended that you use the AWS S3 node.
Prerequisites¶
Ensure that you have configured the S3 server connection in EnOS Management Console > Connection Configurations. For more information, see Connection Configurations.
Node Type¶
Input.
Input and Output Ability¶
This node does not have an entry point and has 1 exit point.
The output is the files according to the URI, displayed in the metadata of the output msg. Each file produces an output msg, which can be used by the expression ${metadata.files} in the next node.
Node Properties¶
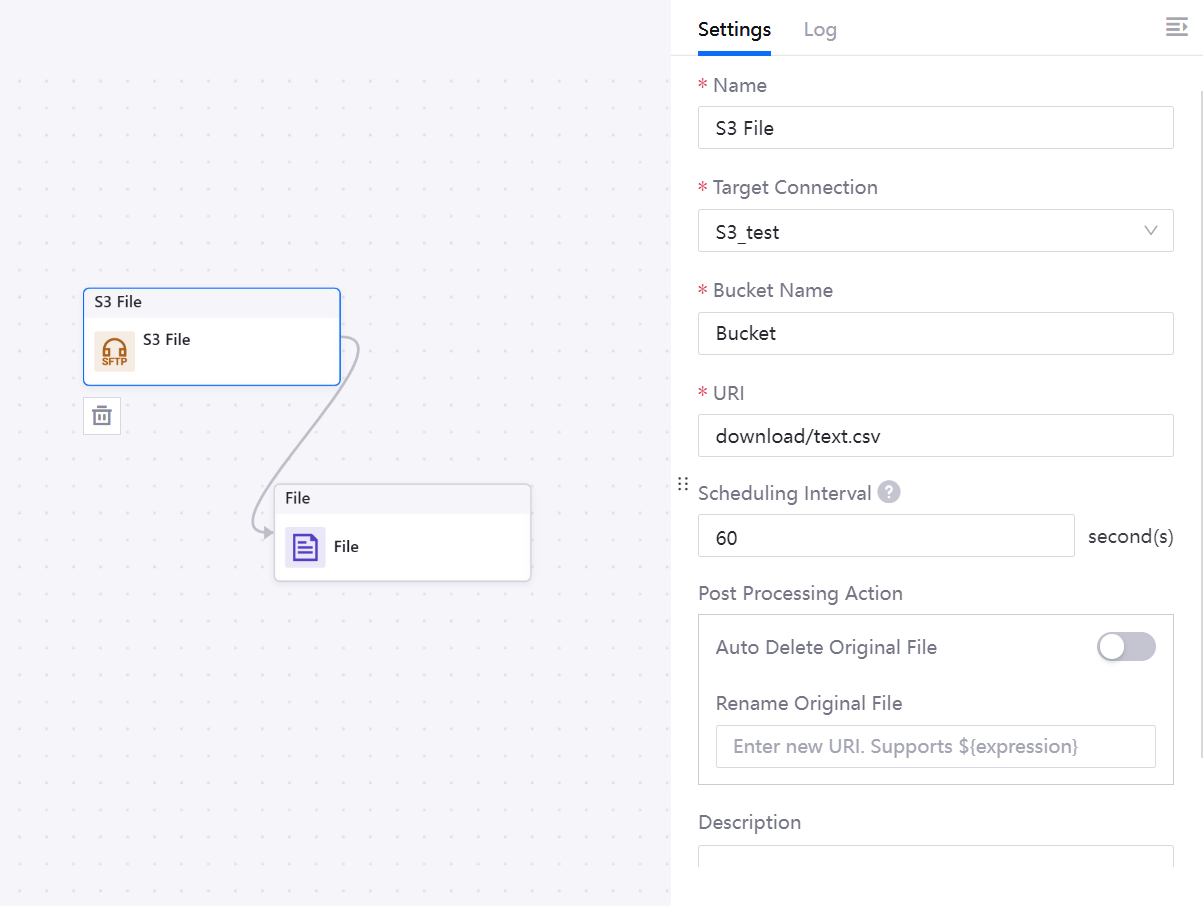
Name
The name for this node.
Target Connection
Choose an S3 server.
Bucket Name
The name of the bucket to be scanned.
URI
The URI of the files to download. Use a delimiter (/) to separate prefixes and file names if required.
Supports all files with the same prefix. For example, enter
download/to scan and download all the files with the prefixdownload/.Supports single files. For example, enter
download/test.csvto scan and download thetest.csvfile with the prefixdownload/.Supports files with the same name but different types. For example, enter
download/testto rename all type files namedtestwith the prefixdownload. File name must be entered exactly.Supports the files at the root level of the bucket. For example, enter
test.csvwithout any prefix to download the test.csv at the root level of the bucket.Does not support wildcards and multiple URIs.
Scheduling Interval
The interval to scan the bucket. The unit is in seconds. Configuring this enables the node to have a self-triggering capability, which can scan the bucket and download files automatically. The interval range is 1-86400 seconds, and the default is 60 seconds.
Note
As it takes some time to download and process files, the actual trigger time may be delayed when the download and processing time exceeds the Scheduling Interval.
Post Processing Action
Auto Delete Original File: After downloading, automatically deletes the files specified in URI. For example, enter
download/in URI with the current switch triggled on to delete all the files with the prefixdownload/after downloading.
Rename Original File: After downloading, renames the original files specified in URI. Use a delimiter (/) to separate prefixes and file names if required.
Supports renaming the prefix. For example, enter
download/in URI andrename/in Rename Original File to rename all files with the prefixdownload/to the prefixrename/. If the file with the prefixrename/exists, it will be overwritten.Supports a single file. For example, enter
download/test.csvin URI anddownload/123.csvin Rename Original File to rename the filetest.csvto123.csv. If the file123.csvexists, it will be overwritten.Supports expressions
${msg.XXX}, which refers to the output msg of the last node of the flow. For example, enterdownload/${msg.expression}.csvin Rename Original File withdownload/test.csvin URL, thedownload/test.csvfile will be renamed to/download/123.csvafter downloading if the last node hasmsg={"expression":"123"}in the output msg.
Description
The description for the node.
Limitations¶
Max download file size: 100M
The interval range: 1-86400 seconds
Does not support wildcards and multiple URIs.
As the AWS S3 server is not managed by EnOS, connection problems could occur due to server downtime or other instances that are not within our control.
Samples¶
Input Sample¶
There is no input msg for this node.
Output Sample¶
Every file scanned in the directory will produce an outlog. For example:
{
"MetaData": {
"files": "[\"/var/data/aws/text.csv\"]"
},
"Body": {}
}