Fixed Batch Pivotor¶
支持按照配置为每个数据(Record)生成分组标签(key),并从本批或缓存数据中将相同标签的数据合并到同一个Record中输出,其主要功能包括:
提供2种生成标签的规则:基于字段的值(field.value)或基于EL表达式来生成标签。
支持开启缓存来实现跨批同标签聚合:开启缓存后(Enable CacheTag=True), 将会以Map(Tag -> List
) 缓存生成的标签,即所有批次该标签对应的数据。输出条件为: 如果某个标签达到了指定的fixedBatchCount批次,则输出。
如果开启提前输出(Enable AheadOutput),即使标签未达到指定的fixedBatchCount批次,也会输出。
如果标签未达到指定的fixedBatchCount批次和提前输出的triggerNumber,则该标签在本批不输出, 会被缓存到Redis中。
支持开启跨批去重(Enable OutputDistinct):
若开启跨批去重,则会把每次输出的标签作为key存入Redis中,用作后面批次的去重参考(过有效期将删除)。
当某个标签已经输出过一次,则该标签即相应的数据(Records)将不参与计算。
配置详情¶
该算子的配置包括General,BasicConfig,GroupKeyConfig,CacheConfig的详细信息,各字段的配置如下:
General¶
名称 |
是否必须 |
描述 |
|---|---|---|
Name |
Yes |
算子名称 |
Description |
No |
算子描述 |
Required Fields |
No |
数据必须包含的字段,如果未包含指定字段,则record将被过滤掉 |
Preconditions |
No |
数据必须满足的前提条件,如果不满足指定条件,则record将被过滤掉 |
On Record Error |
Yes |
对错误数据的处理方式: |
Send to Error:发送至错误中心 Stop Pipeline:停止流任务运行 |
BasicConfig¶
名称 |
是否必须 |
描述 |
|---|---|---|
Points |
Yes |
数据输入点,格式为:{模型标识}::{测点标识} |
Output PointId |
Yes |
数据输出点,格式为:{模型标识}::{测点标识} |
QualityControl Level |
No |
数据质量位选择,表示该算子可以支持或需要处理哪些类型的数据质量。 |
GroupKeyConfig¶
名称 |
是否必须 |
描述 |
|---|---|---|
Group-Key Generate Method |
Yes |
选择生成分组标签(key)的方式,可选byField,byELExpress,或byFieldAndELExpress |
Fields.HowToTag |
Yes |
定义具体生成字段,可选FieldAsKey或InputAsKey |
Fields.FieldTag |
No |
当选择FieldAsKey时,输入FieldTag |
Fields.InputTag |
No |
当选择InputAsKey时,输入InputTag |
CacheConfig¶
名称 |
是否必须 |
描述 |
|---|---|---|
Enable CacheTag |
No |
选择是否开启缓存,实现跨批同标签聚合 |
FixedBatchNumber |
No |
开启跨批聚合时,选择跨批聚合的批次数量。如选择CustomBatchNum,则在Batch Count一栏中输入自定义的批次数量。 |
Enable AheadOutput |
No |
选择是否开启提前输出。开启时,即使标签未达到指定的FixedBatchNumber批次数量,也会输出。 |
Trigger Number By Expression |
No |
开启提前输出时,输入触发提前输出的批次数量 |
Enable OutputDistinct |
No |
选择是否开启跨批去重。开启时,同一标签最多输出一次 |
ExpireRule |
No |
选择缓存数据失效的时间 |
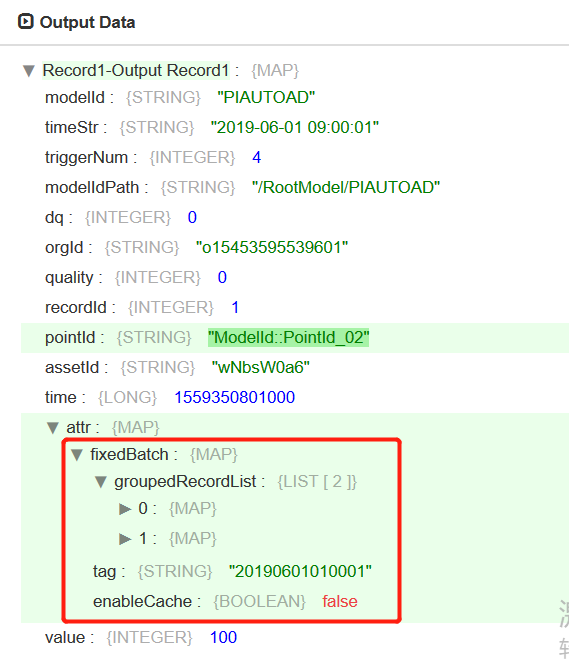
输出结果¶
该算子的输出结果包含在Attribute结构体中,各字段的描述如下:
名称 |
数据类型 |
描述 |
|---|---|---|
fixedBatch |
Map |
具有相同标签的记录集合 |
输出示例¶