维护流数据处理任务¶
当流数据处理任务发布上线后,可在 流运维 页面上对已发布的任务进行各种运维操作,包括运行资源配置、监控告警配置、启停系统任务、启停用户任务、查看任务运行状态等操作。
配置运行资源
配置任务运行资源之前,需确保组织已经申请运行流数据处理任务的资源:
Standalone模式:需申请Standalone模式运行资源
集群模式:需申请集群模式运行资源
申请资源的步骤,请参考 资源申请和扩容。
通过以下步骤,设置流数据处理任务的运行模式,并配置任务运行需要的资源:
进入 流运维 页面,在 用户流任务列表 标签下查看已发布的流数据处理任务。新发布的流数据处理任务的默认状态为 PUBLISHED。
从任务列表的 操作 列中,选择 … > 运行配置,在弹窗中配置流数据处理任务所需的运行资源。
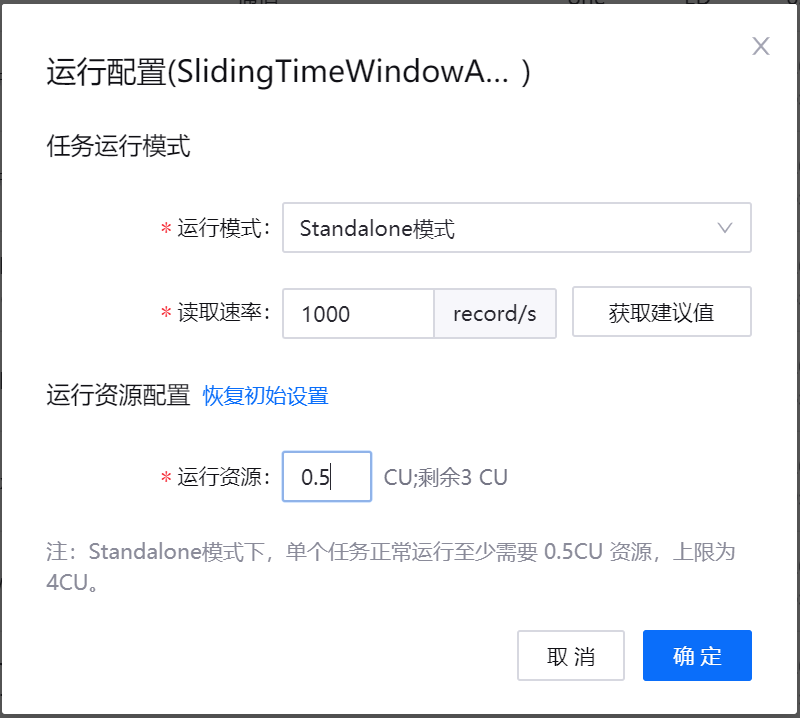
如以单机模式运行流数据处理任务,从 运行模式 下拉菜单中,选择 Standalone模式,输入读取数据的速率,然后输入运行任务所需的资源(CU数量)。
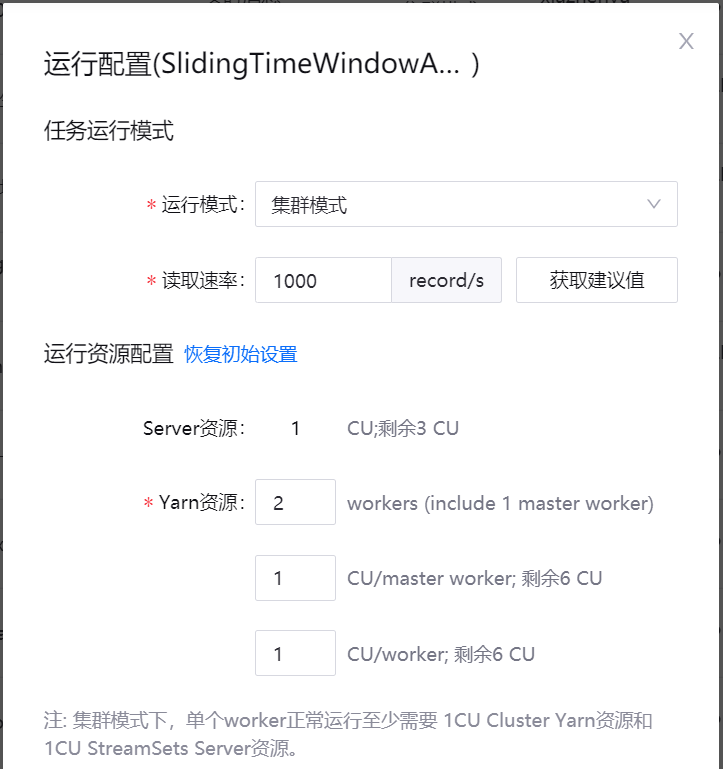
如以集群模式运行流数据处理任务,从 运行模式 下拉菜单中,选择 集群模式,输入读取数据的速率,然后配置运行任务所需的Yarn资源。
如需配置集群模式高级参数,点击 添加配置项,并输入需要使用的参数和对应的值。对可配置的高级参数的说明,参见 集群模式高级参数。
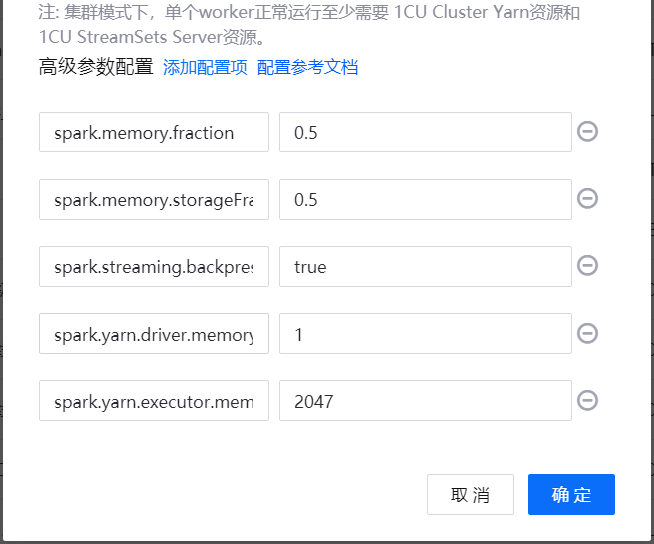
点击 确定,完成运行资源配置。
集群模式高级参数
参数名称 |
描述 |
|---|---|
spark.streaming.backpressure.enabled |
指定是否启用 Spark Streaming 内部的反压机制。启用后,Spark Streaming 能够根据当前的批数据调度延迟和处理时间来控制系统接收数据的速率,从而使系统处理数据的速度与接收数据的速度一致,以避免数据堆积。在系统内部,这是通过动态收集系统的一些数据来自动地适配集群的数据处理能力。 |
spark.yarn.driver.memoryOverhead |
在集群模式下,为每个 Driver 分配的堆外内存(单位为MB)。该堆外内存是 JVM 进程中除 Java 堆以外占用的空间大小,一般会随着 Executor 大小而增长(通常为6-10%)。 |
spark.yarn.executor.memoryOverhead |
为每个 Executor 分配的堆外内存(单位为MB),该堆外内存是 JVM 进程中除 Java 堆以外占用的空间大小,一般会随着 Executor 大小而增长(通常为6-10%)。 |
spark.memory.fraction |
设置存储内存和执行内存占用堆内存的比例(默认值为0.6)。这个参数的值越低,则发生溢出和缓存数据移出的频率就越高。配置此参数的目的是为内部元数据、用户数据结构、和不精确的数据大小估算预留内存。建议设置为默认值。 |
spark.memory.storageFraction |
设置存储内存占用堆内存的比例(默认值为0.5)。这个参数的值越高,可用于执行的工作内存就越少,任务可能会更频繁地溢出到磁盘。建议设置为默认值。 |
配置监控告警¶
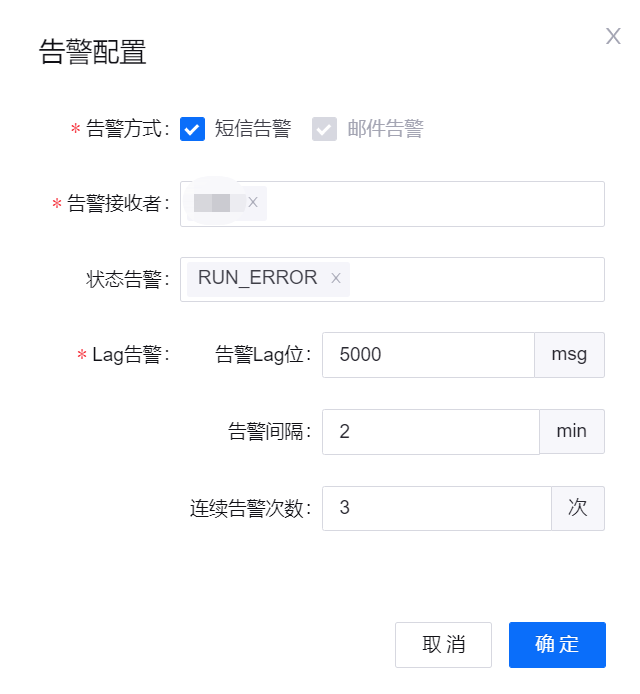
流运维功能支持对流数据处理任务配置状态和Kafka Lag告警。目前告警配置支持通过邮件或短信告警,当任务运行出现问题时,能通过邮件或短信通知任务负责人。
通过以下步骤,完成对流数据处理任务的告警设置:
从任务列表的 操作 列中,选择 … > 告警配置,在弹窗中配置流数据处理任务告警规则。
选择告警的方式、接收者、触发告警的任务状态、触发告警的Lag阈值等,然后点击 确定。
启动系统任务¶
在启动流数据处理任务之前,需确保对应的系统任务已启动并运行。实时通道和离线通道各配套两个系统任务,即数据写入和数据读取任务。
通过以下步骤,启动系统流处理任务:
进入 流运维 页面,在 系统流任务列表 标签下查看已自动匹配生成的系统流任务。
在系统流任务列表的 操作 列中,点击 启动 键
 启动对应的系统任务。系统任务开始运行后,即可启动对应的用户流数据处理任务。
启动对应的系统任务。系统任务开始运行后,即可启动对应的用户流数据处理任务。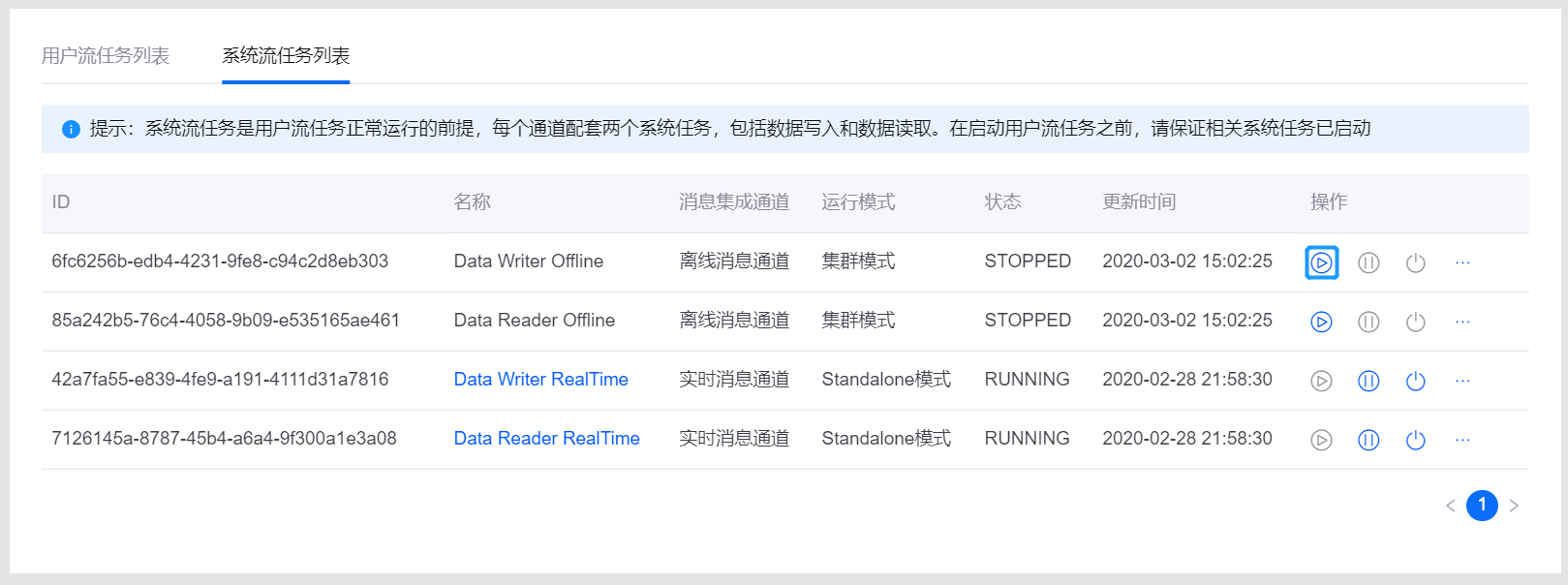
运维流数据处理任务¶
在 流运维 页面任务列表中,可对流数据处理任务进行如下运维操作:
启动:点击 启动 键
开始运行任务。任务开启后,即可在流数据处理系统中开始持续运行。暂停:对运行中的任务,点击 暂停 键
 。暂停任务后,缓存的数据会被暂时保留。当重新启动任务时,会继续暂停前的状态开始计算,但暂停时间不得超过24小时。
。暂停任务后,缓存的数据会被暂时保留。当重新启动任务时,会继续暂停前的状态开始计算,但暂停时间不得超过24小时。停止:对运行中的任务,点击 停止 键
 。停止任务后,任务运行过程中的中间结果会被清除,请谨慎操作。当重新启动任务时,任务会继续从停止前的数据开始处理,但是任务停止前的计算结果不会被保存。
。停止任务后,任务运行过程中的中间结果会被清除,请谨慎操作。当重新启动任务时,任务会继续从停止前的数据开始处理,但是任务停止前的计算结果不会被保存。查看任务配置:从任务列表的 操作 列中,点击 … > 查看配置,查看任务的详细配置。
导出任务配置:从任务列表的 操作 列中,点击 … > 导出配置,可下载任务配置文件。
监控流任务运行状态¶
对运行中的流数据处理任务,可监控其实时运行状态:
在流数据处理任务列表中,查看运行中的流数据处理任务。
在对应任务的 操作 列中,选择 … > 运行监控,在弹窗中查看流数据任务的运行情况:
Producer Rates: 查看Kafka产生数据的速率
Consumer Rates: 查看任务消费数据的速率
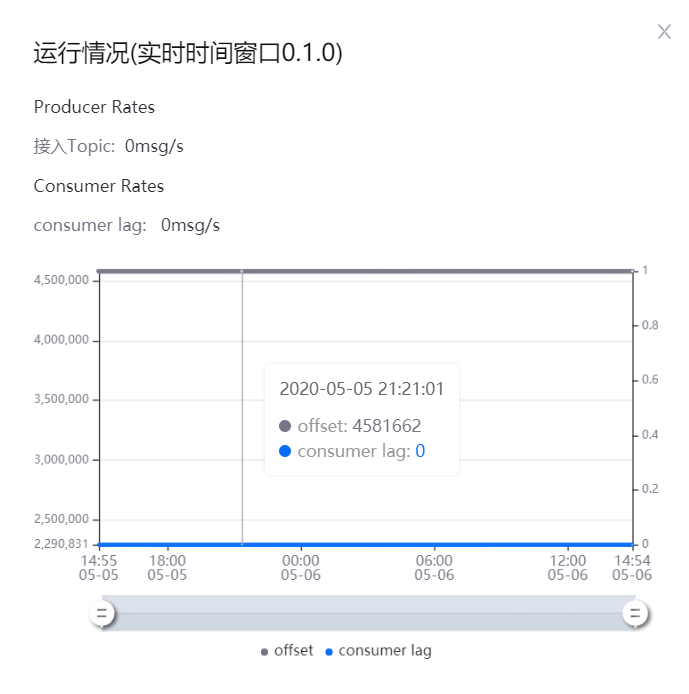
如任务消费数据的速度存在延迟,可通过增加任务运行资源的方法,提高任务运行的效率。
查看流任务运行结果¶
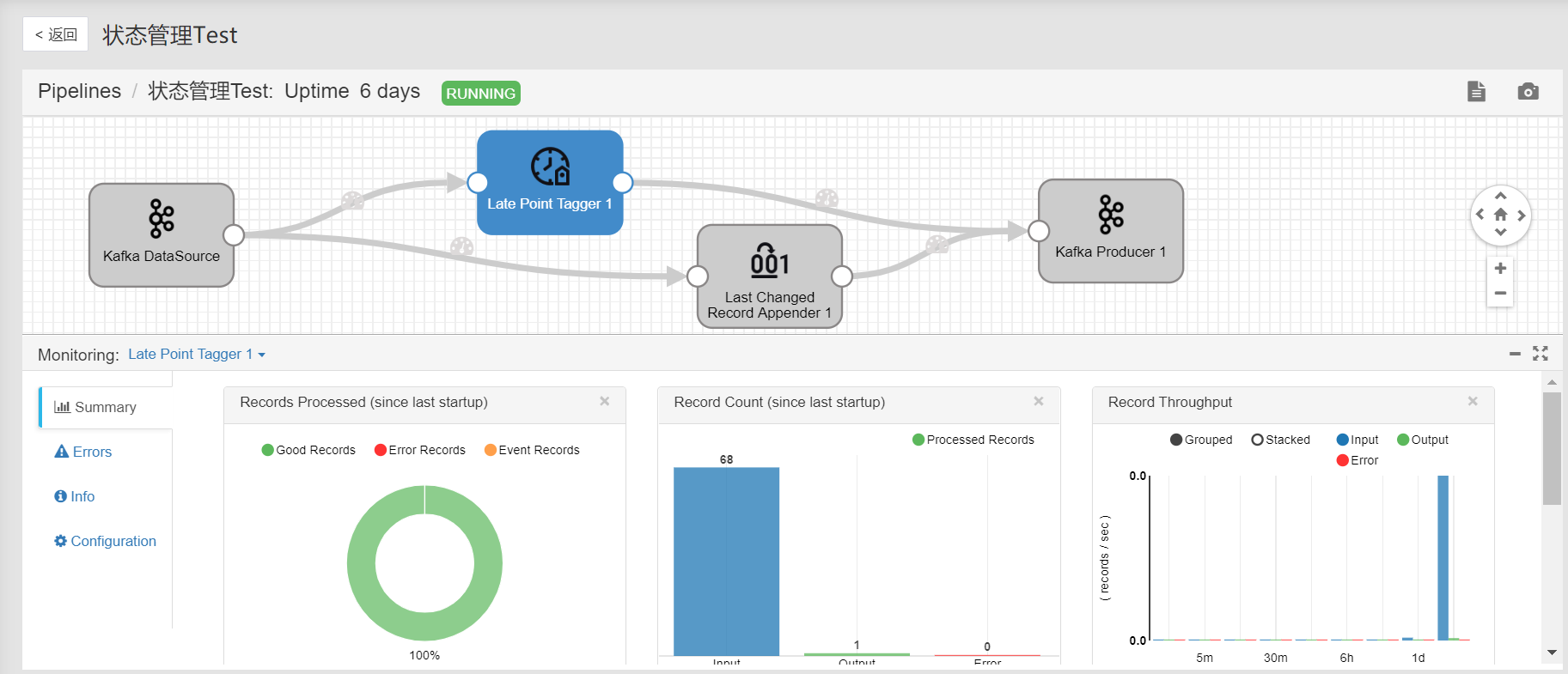
在 流运维 页面,在 名称 一栏中,点击已启动的任务名称,可查看任务的运行情况:
Summary: 查看任务运行情况总结,比如整体处理记录统计、各个时间段聚合情况。
Log: 点击页面右上角 View Logs 图标,可查看任务运行日志。