Latest Record Merger*¶
This stage generates group tags based on the specified expression. Multiple input points are grouped by the generated tags and output the points by groups. When the specified point arrives, an output will be triggered. The functions of this stage include:
Support inputting multiple measurement points and supporting multiple input points as calculation trigger points.
Multiple measurement points are supported, the MeasurementId of the input point is replaced with the corresponding output MeasurementId.
This stage cannot guarantee idempotence of the calculation results due to failure retries caused by any reasons, such as cluster node exceptions.
Incompatible with old data formats, i.e. cannot filter data by
ModelId::PointId.
Configuration¶
The configuration tabs for this stage are General, Basic, Input/Output, MergerConfig, and CacheConfig.
General¶
Name |
Required? |
Description |
|---|---|---|
Name |
Yes |
The name of the stage. |
Description |
No |
The description of the stage. |
Stage Library |
Yes |
The streaming operator library to which the stage belongs. |
Required Fields |
No |
The fields that the data records must contain. If the specified fields are not included, the record will be filtered out. |
Preconditions |
No |
The conditions that must be satisfied by the data records. Records that do not meet the conditions will be filtered out. For example, |
On Record Error |
Yes |
The processing method for error data.
|
Basic¶
Name |
Required? |
Description |
|---|---|---|
Quality Filter |
No |
Filter the data according to the data quality. Only records that meet the quality conditions will be processed by this stage. |
Input/Output¶
Name |
Required? |
Description |
|---|---|---|
Input Measurement |
Yes |
Input points of a single rule, i.e. measurement points that need to be grouped and aggregated. |
Is Trigger |
No |
Specify whether to set the point as the trigger for processing. |
Output Measurement |
Yes |
The output point of a single rule, i.e. the measurement point that carries the output result. |
MergerConfig¶
Name |
Required? |
Description |
|---|---|---|
Merged By Expression |
Yes |
Specify the expression for generating the tags that are used to merge the latest records. If the expression contains other identification information such as timestamp, a large amount of data might be generated. When choosing to use Redis as data storage, it is necessary to evaluate the impact on data storage and prepare corresponding plans. |
Cache Expire Time (Minute) |
Yes |
Specify the cache expiring time after the tags are not updated. |
CacheConfig¶
Name |
Required? |
Description |
|---|---|---|
Cache Type |
Yes |
Select the storage type for cache data. Options are Redis and Local storage.
|
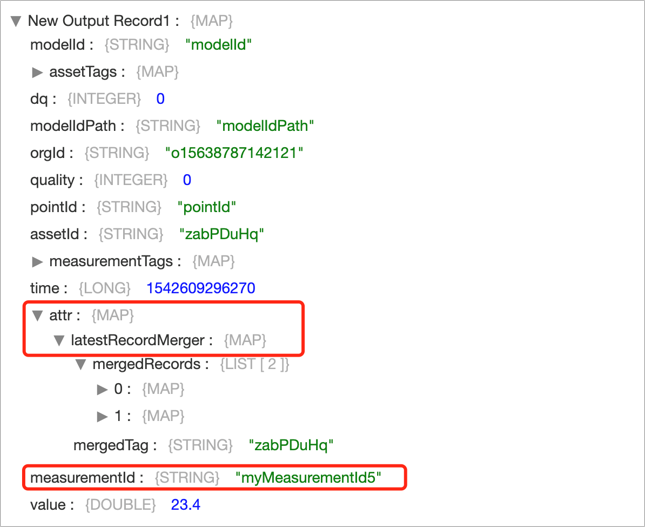
Output Results¶
The output results of this stage are included in the attr struct. The description of the fields are as follows:
Name |
Data Type |
Description |
/attr/latestRecordMerger |
Map |
The data object after merging. |
mergedTag |
String |
The tags that are generated based on the EL expression. |
mergedRecords |
List |
The list of records after merging. |
Note
The values of modelIdPath, pointId, and modelId in the output of this operator are the default strings: modelIdPath, pointId, and modelId respectively.
Output Example¶