EnOS Stream Processing Service Overview¶
What is Stream Processing¶
Stream processing is a big data processing technology. In stream processing process, the amount of input data is not limited, and there is no scheduled start time or end time. The input data forms a series of events, which enter the processing engine in the form of continuous “streams” and are calculated in real time. For example, stream processing can detect a single fraudulent transaction in a stream that contains millions of legitimate purchases, act as a recommendation engine to determine what advertisements or promotions a particular customer needs during shopping, analyze device log files, or receive alerts by querying the data stream from temperature sensors and detecting when the temperature reaches the freezing point.
EnOS™ Stream Processing¶
Powered by Apache Spark™ Streaming, and customized and optimized by Envision, the EnOS™ Stream Processing engine has high scalability, high throughput, and high fault-tolerance. EnOS Stream Processing Service aims to help you cope with the velocity, volume, and variety of data by increasing the data development and access efficiency, enforcing data quality and compliance, and optimizing data storage, thereby reducing your total cost of ownership on your IoT data.
The architecture of EnOS Stream Processing service is shown in the figure below.
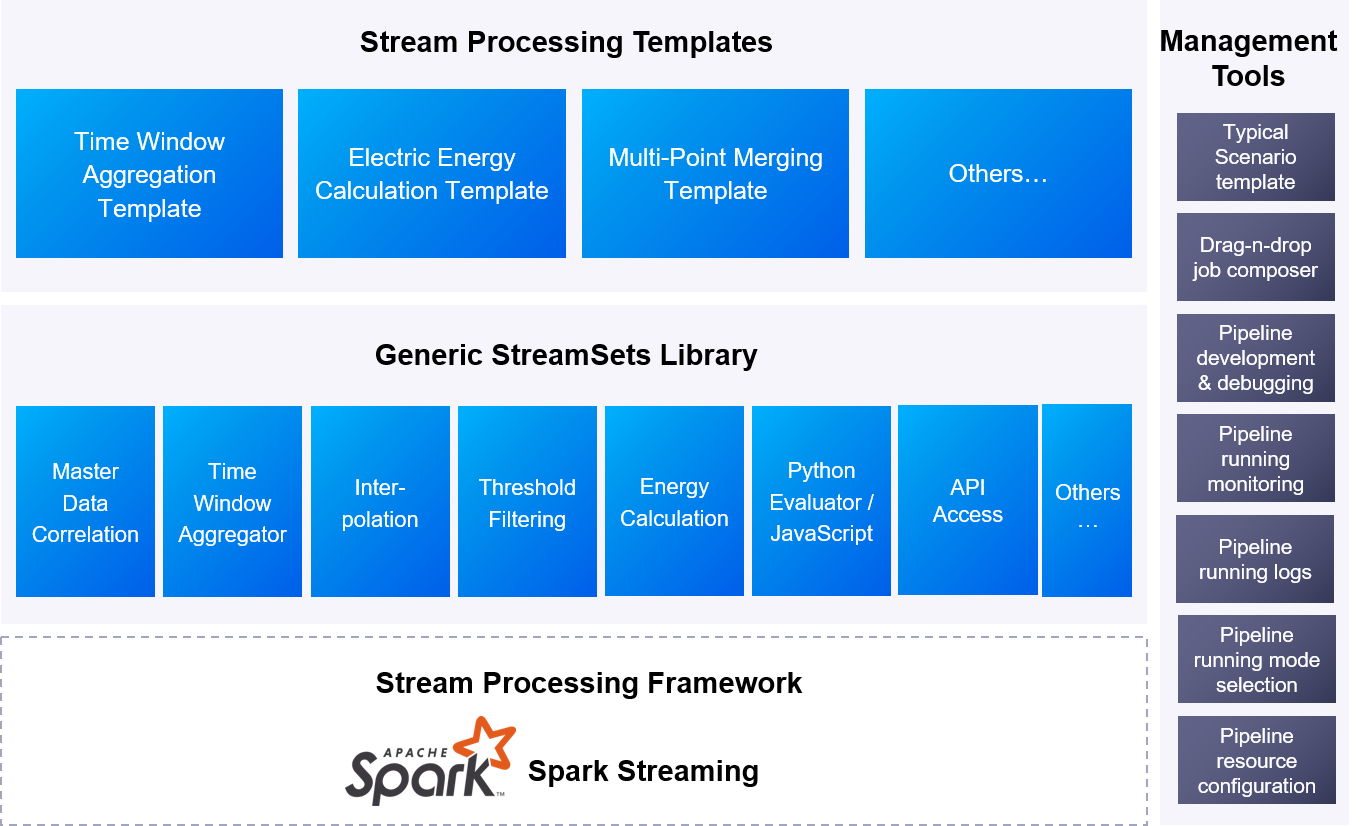
EnOS Stream Processing service also accumulates common algorithms for processing IoT data. Application developers can develop stream data processing pipelines through simple template configuration. In addition, EnOS Stream Processing Service provides a number of data processing templates and operators in the energy field, helping data engineers to develop data processing solutions quickly without coding, greatly improving the efficiency of data development and reducing the development threshold.
Data Processing Workflow¶
EnOS Stream Processing Service procedure is as follows.
Process raw data
The original measurement point data is sent to Kafka through the EnOS connection layer. The messages received are analyzed by the stream computing service. Before processing, the data is filtered according to the specified threshold. The data exceeding the threshold will be processed by the interpolation algorithm.
Perform calculation
In this step, the data is computed by the defined algorithm in the processing strategy.
Store computed output
The data from the streaming module flows into In-memory Database (IMDB) and Kafka, and the downstream continues to subscribe to all data from Kafka and record them to the Time Series Database (TSDB) or other storage systems. The stored data can be used as the data source for offline data processing and further processing and analysis.