Tutorial Overview¶
Application Scenarios¶
In the wind power generation business, the weather conditions have a great influence on the power generation, and the business has a strong demand for power generation forecast. This tutorial shows the complete workflow of data preparation, feature processing, model training, model version staging, model publishing, model file-based or model service-based prediction, based on wind power algorithms and weather sample data. Through this simple machine learning example, you can get familiar with the use of operators as well as design and orchestration capabilities in MI Pipelines in EAP (Enterprise Analysis Platform), and then use them flexibly in different application scenarios.
This tutorial focuses on the use of MI Pipelines for this scenario, covering most of the commonly used operators, such as logical operators and model operators, etc. You can refer to other sections for more information about other modules such as MI Lab, Dataset, or MI Hub.
Target Audiences¶
Those with no data science background, need a preliminary understanding of EAP product features
Those with data science background, need to understand EAP product features in depth
Those with data science background, need to complete the engineering implementation task of specific machine learning scenarios through EAP
Those with data science background, need a complete sample reference to design a specific scenario Pipeline
Overall Architecture¶
The Pipelines design for the wind power prediction scenario is divided into two branches, training and prediction, and the tasks to be run are divided by the input global parameter tasktype, as shown in the following figure.
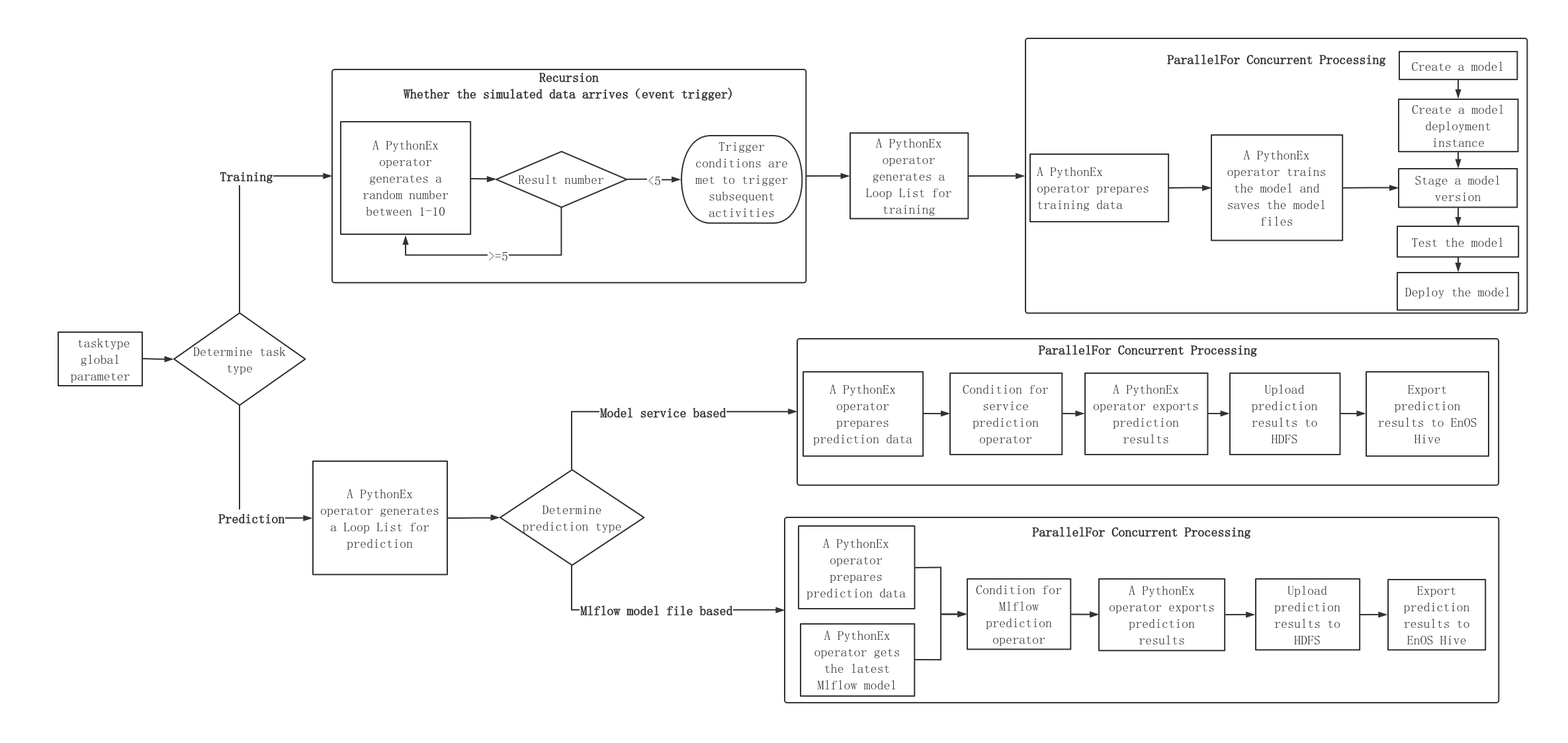
In which
The training tasks enable you to access and pre-process the raw data, create and train the models, deploy model versions, and so on.
The prediction tasks enable you to receive data, predict based on model services or model files, and save the prediction results to HDFS and EnOS Hive for further analysis.
Prerequisites¶
You have understood the functions and usage methods of various operators in EAP MI Pipelines. For more information, see Operator Reference.
Dataset: This tutorial uses a sample dataset that is installed and deployed with the EAP module.
Resource pool: Resource (including CPU, memory, storage, etc.) are required for EAP installation and deployment, pipelines and model deployments. Make sure your organization (OU) has requested Batch Processing - Queue, Data Warehouse Storage, File Storage HDFS and ML Model - Container Resources through the Resource Management page for storing and processing data required for model training. For more information, see Resource Management on EnOS.
Environment configuration: EAP-related components need to be installed independently under an OU.
Units¶
This tutorial contains the following units: