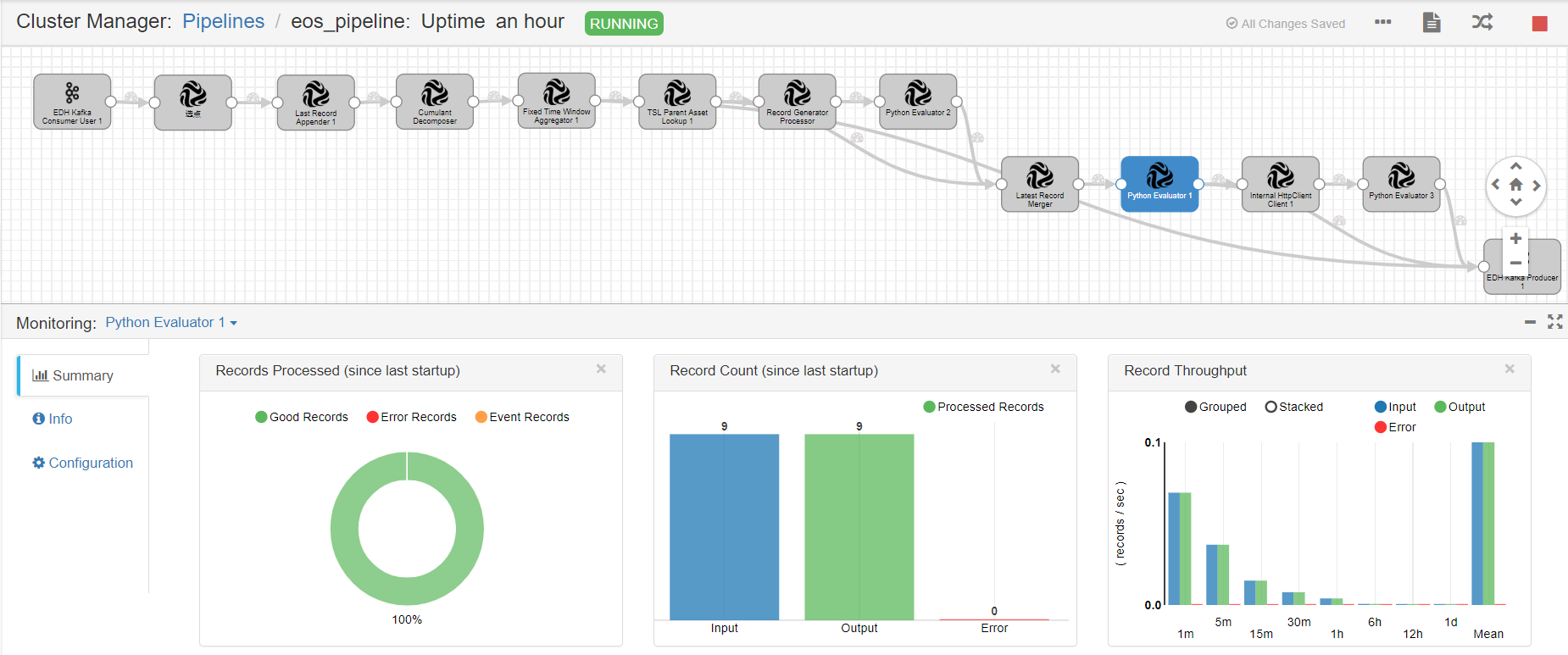
Unit 4. Developing a Stream Data Processing Job¶
The EnOS Stream Processing Service provides a user-friendly UI for designing stream data processing jobs (pipelines) with StreamSets operators (stages). Developers can quickly configure a pipeline by adding operators to the pipeline, thus completing data ingestion, filtering, processing, and storage tasks without any programming involved.
In this unit, we will develop a stream data processing job with StreamSets operators to calculate the daily energy production of wind turbines, the daily energy production of wind farms, and the carbon reduction data of wind farms.
To meet the requirements of the above scenario, we will use the following StreamSets operators.
Operator |
Description |
|---|---|
Data Source |
Get the complete data records from Kafka. |
Point Selector |
Specify the data records of the eos_turbine::ammeter measurement point as the input data. |
Last Record Appender |
Append the last record of the eos_turbine::ammeter measurement point of a wind turbine to the attr field of the current record. |
Cumulant Decomposer |
Get the delta value between the current record and the last record in the attr field for calculating the energy production data in the time interval. |
Fixed Time Window Aggregator |
Calculate the daily energy production data of a wind turbine by summing up the energy production data in all time intervals of the day. The output results will be used for further calculation and sent to Kafka as well. |
TSL Parent Asset Lookup |
Query the parent node (wind farm) of a wind turbine on the asset tree. |
Record Generator |
Generate a new record for triggering the calculation of wind farm energy production by a 1-minute frequency. |
Python Evaluator 1 |
Append parent node information to the generated triggering point and tag the triggering point with Python scripts. |
Latest Record Merger |
Merge the triggering point and the daily energy production data of a wind turbine by the parent node information. |
Python Evaluator 2 |
Calculate the daily energy production data of a wind farm by summing up the daily energy production data of all wind turbines with Python scripts. The output results will be used for further calculation and sent to Kafka as well. |
Internal HTTP Client |
Get the carbon reduction parameter by calling the EnOS Get Asset API. |
Python Evaluator 3 |
Calculate the daily carbon reduction of a wind farm with Python scripts. The output results will be sent to Kafka. |
Data Destination |
Send all the output results to Kafka. |
The business scenario is depicted in the following figure.

For detailed information about the StreamSets operators, see Calculator Library 0.0.4 Documentation.
Creating a StreamSets Pipeline¶
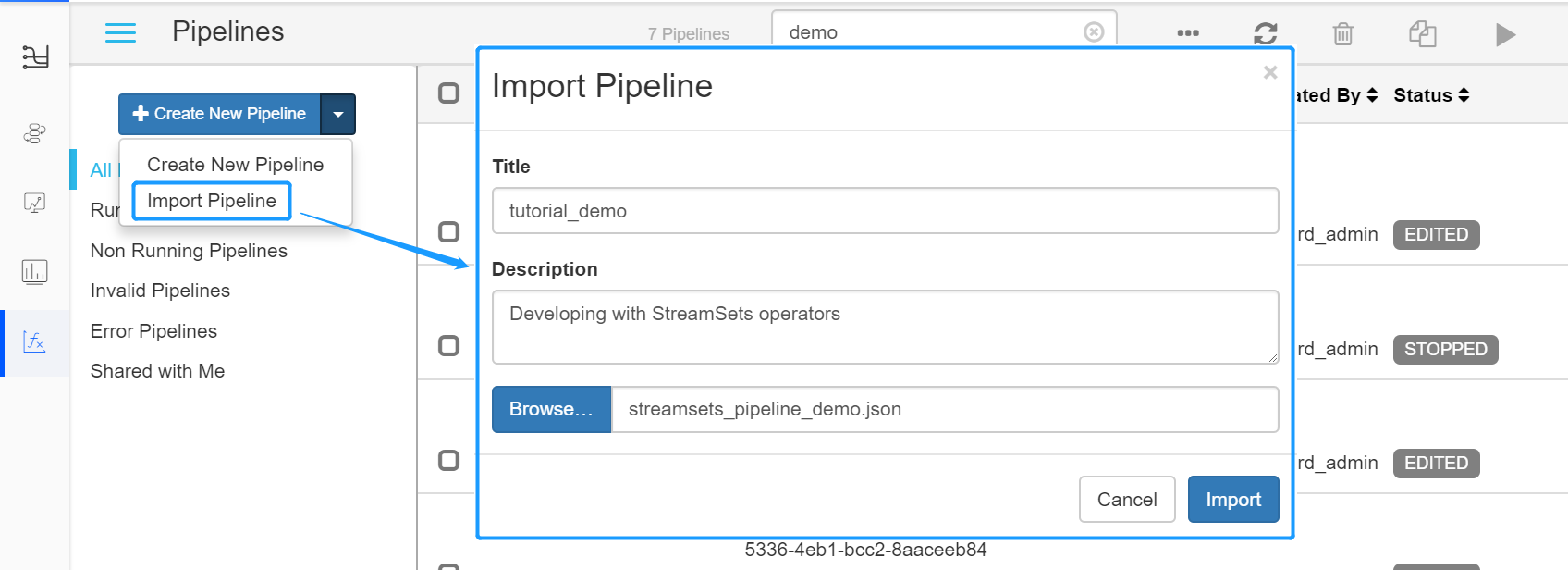
Download the StreamSets pipeline configuration template from https://support.envisioniot.com/docs/data-asset/en/2.1.0/_static/streamsets_pipeline_demo.json (right click the link and save the
streamsets_pipeline_demo.jsonfile to a local directory).Log in to the EnOS Management Console, select Stream Processing > StreamSets, click the triangle beside the Create New Pipeline button, and select Import Pipeline.
On the Import Pipeline window, enter a pipeline title and description, click Browse …, navigate to and select the configuration template file, and click Import.
Set the yarn queue for the new pipeline. Click the Cluster tab, and set the value of the
spark.yarn.queuefield asroot.streaming_{orgId}, in whichorgIdis the organization ID (can be retrieved from the IAM > Organization Profile page of EnOS Management Console).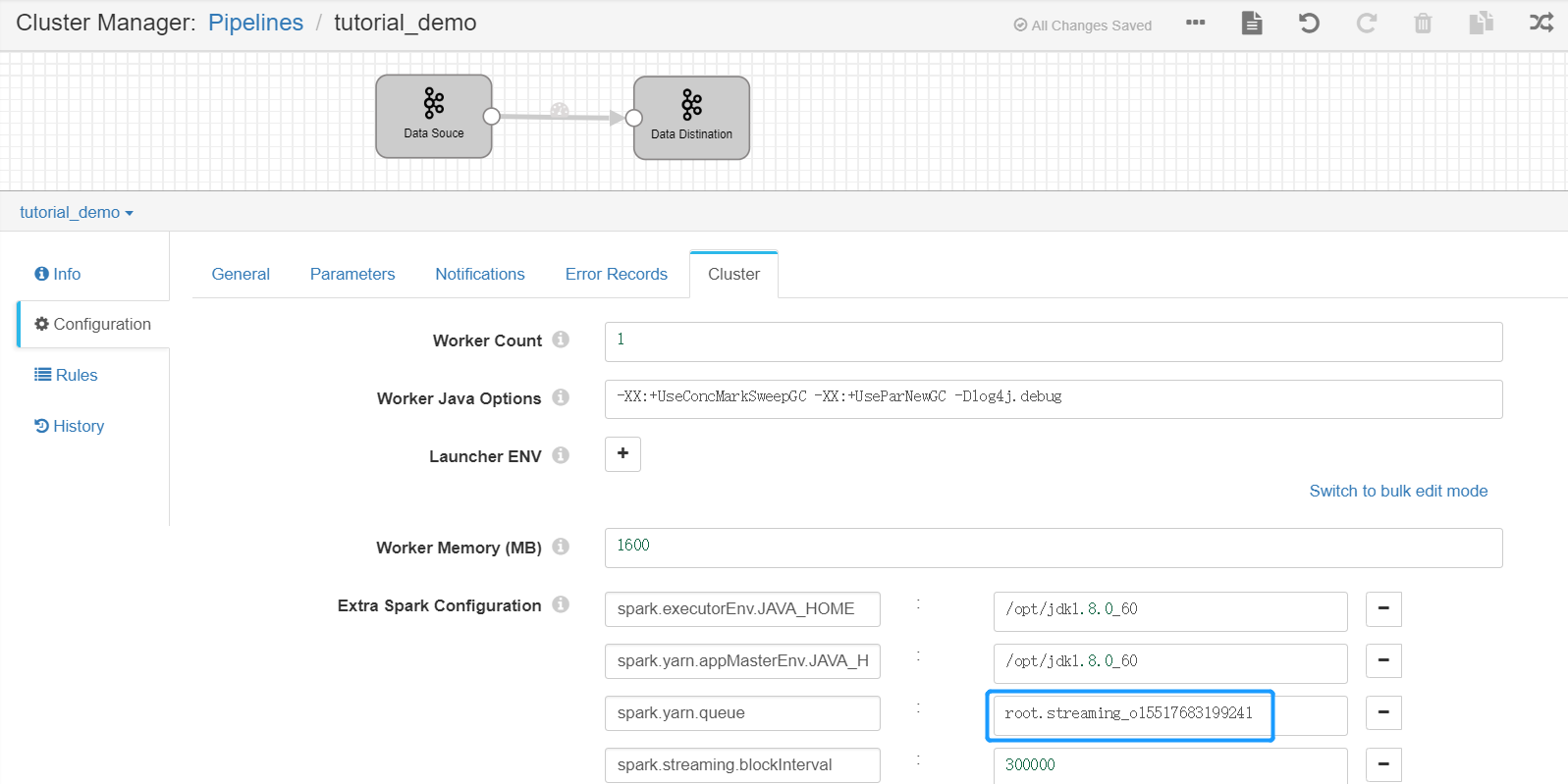
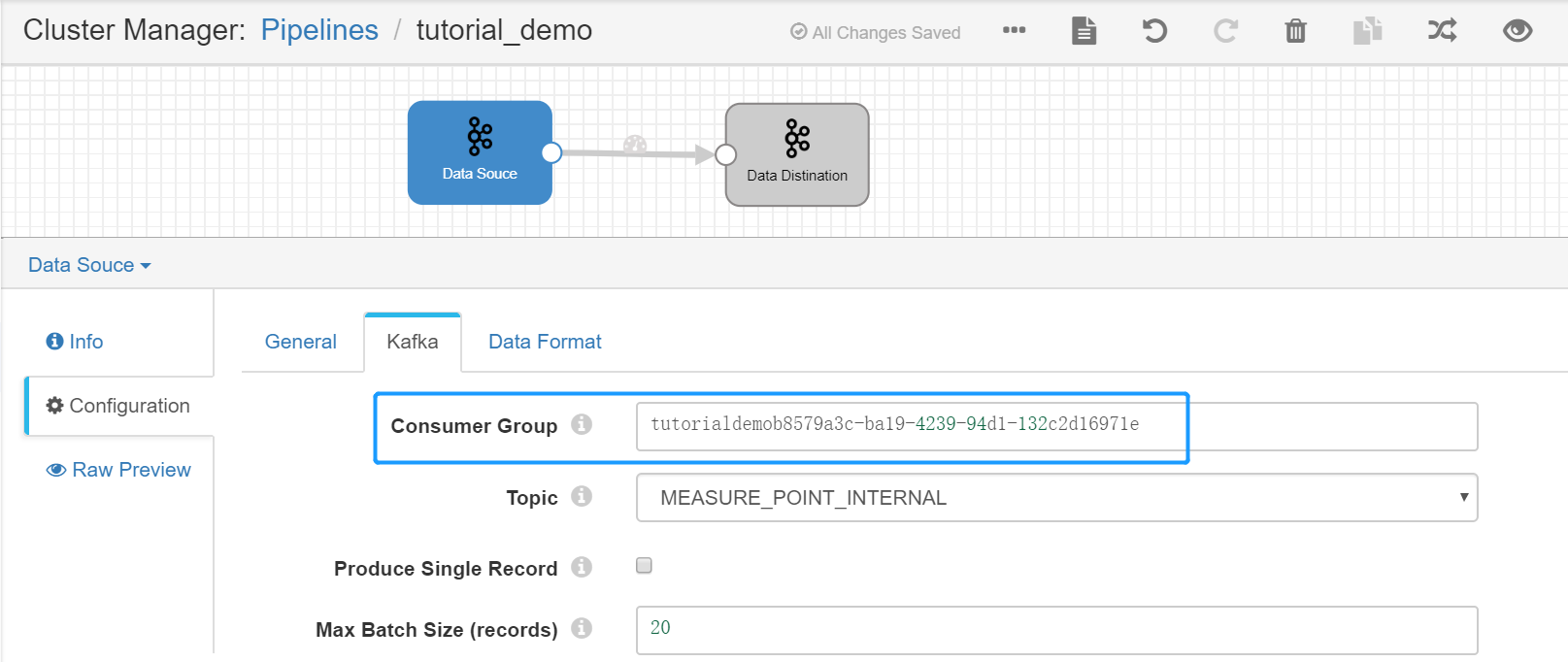
Set the Kafka Consumer Group. Select the Data Source stage, click the Kafka tab, and set the value of the Consumer Group parameter (which must be unique within the organization). It is recommended to use the pipeline ID as the consumer group.
Adding Operators to the Pipeline¶
Now we can add the operators and connect the operators with arrows to form the pipeline.
Select the arrow between the Data Source and Data Destination operators and click the Delete icon to remove the connection.

Click the Stage Library icon in the upper right corner of the page and select EDH Streaming Calculator Library 0.0.4.
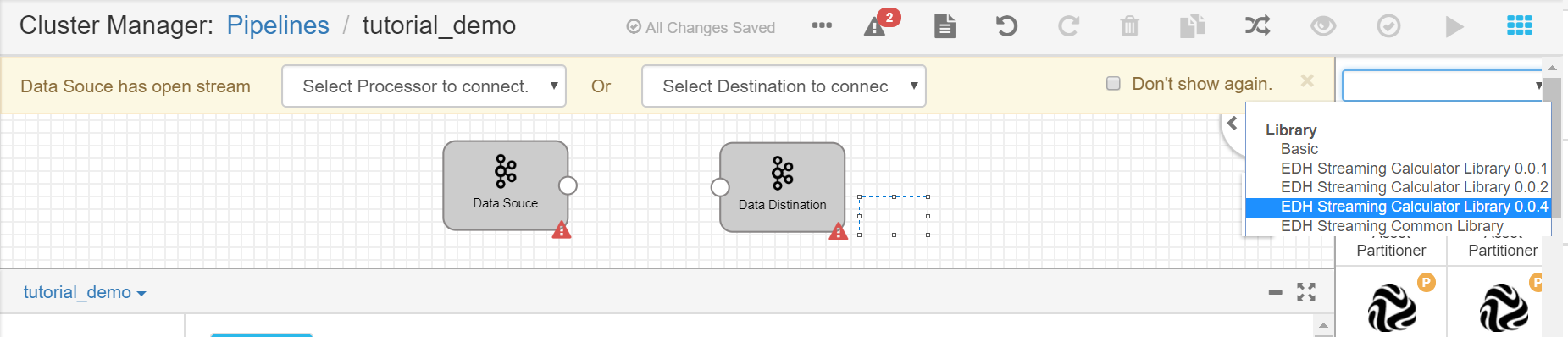
From the list of operators, click the Point Selector operator to add it to the pipeline canvas.
Connect the output point of the Data Source operator to the input point of the Point Selector operator.
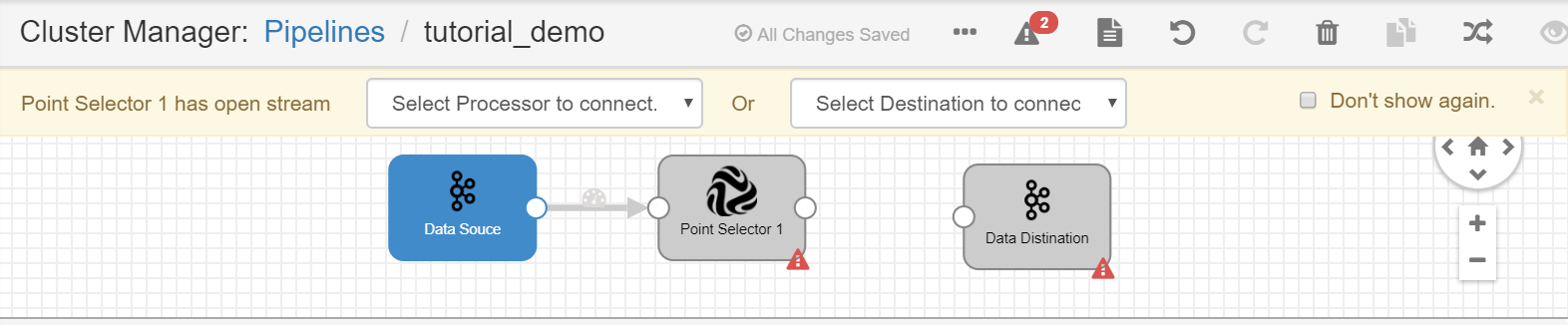
Repeat steps 3 and 4 to add the remaining operators to the pipeline and connect them by the order as shown in the following figure.
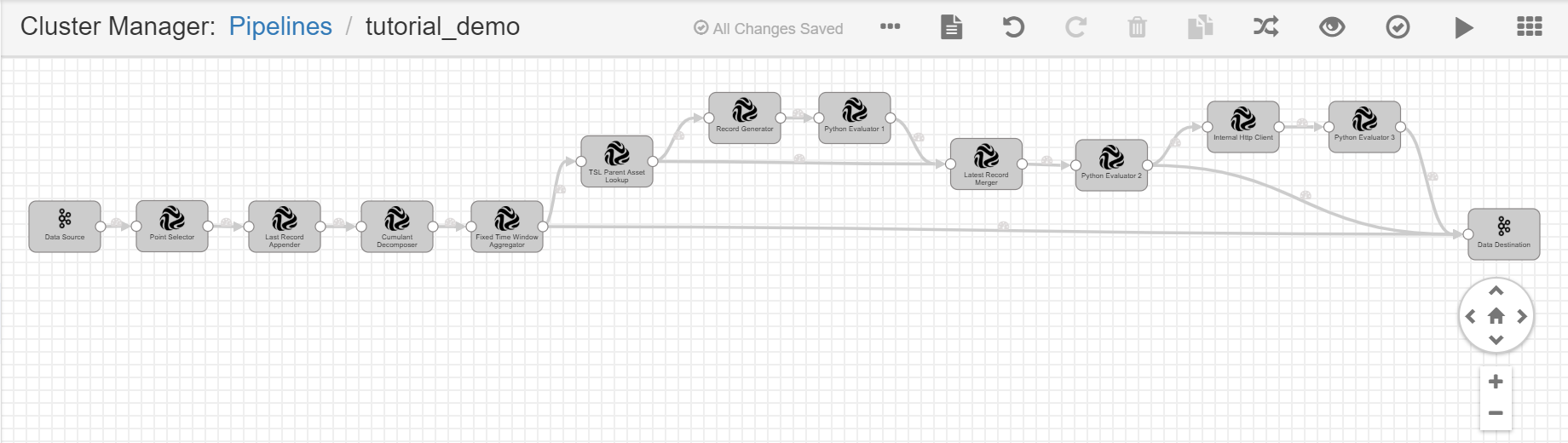
Click the Auto Arrange icon
 to align the display of operators in the pipeline.
to align the display of operators in the pipeline.
Configuring the Operator Parameters¶
After the pipeline is created, we can now configure the parameters for the added operators. Select the operators and complete the configuration for each tab. For the General and Basic tabs, use the default configuration. For the other tabs, follow the instructions below for each operator.
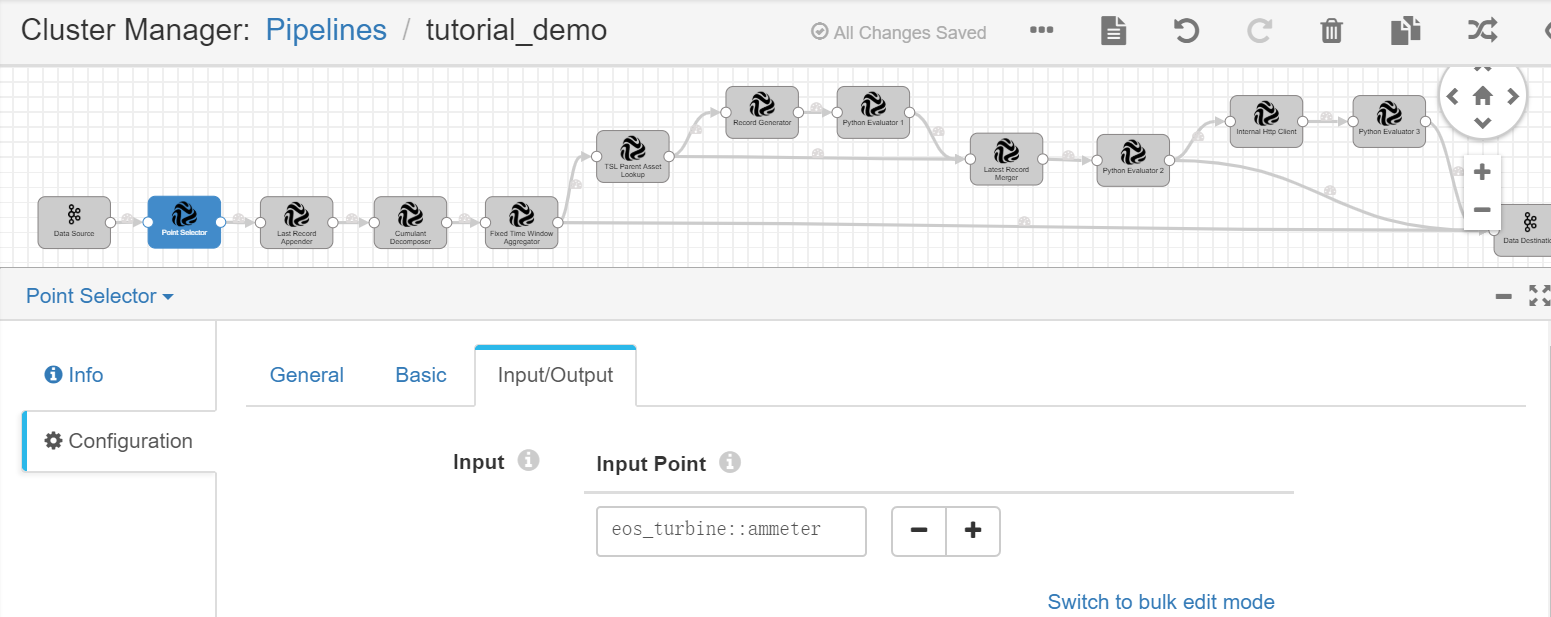
Point Selector¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::ammeter |
Gets the ammeter point data from Kafka as the input. |
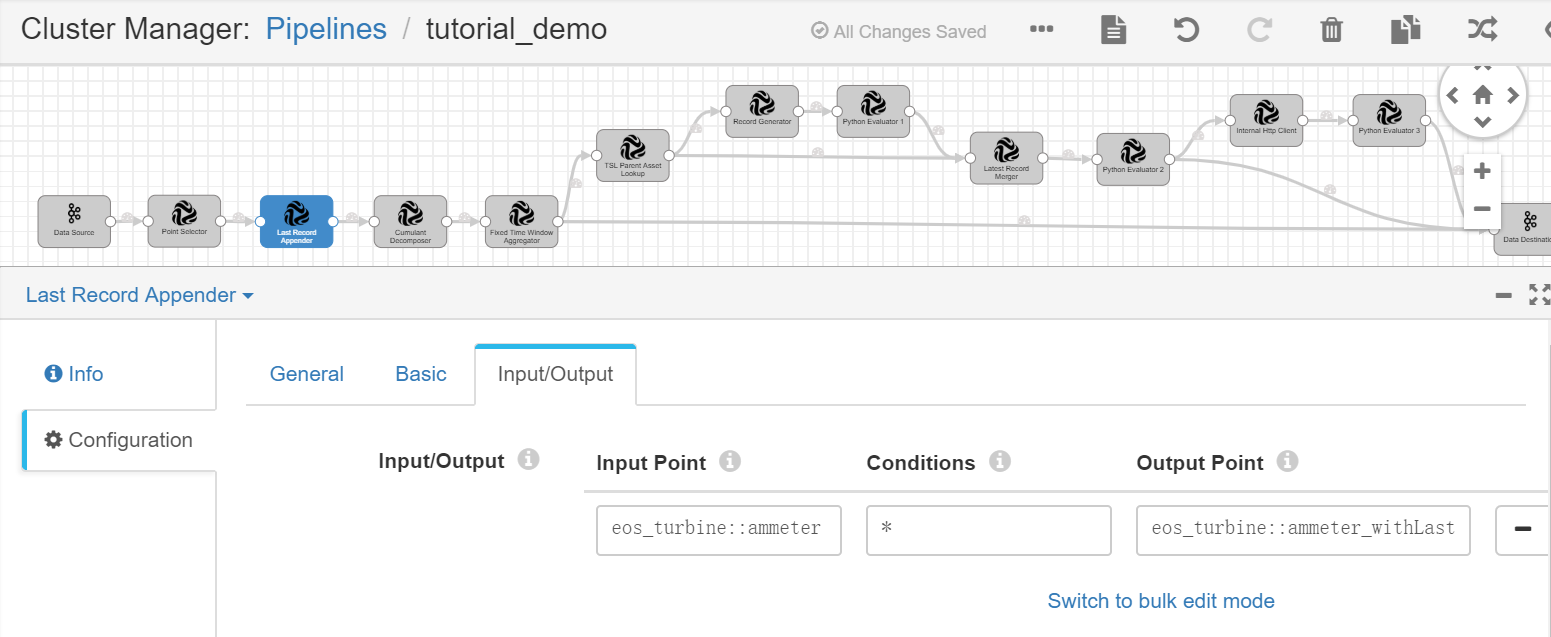
Last Record Appender¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::ammeter |
Receives the wind turbine energy production data as input. |
Conditions |
* |
Always replace the current record with the last record. |
Output Point |
eos_turbine::ammeter_withLast |
Receives the output result, which contains the current and last record of wind turbine energy production data. |
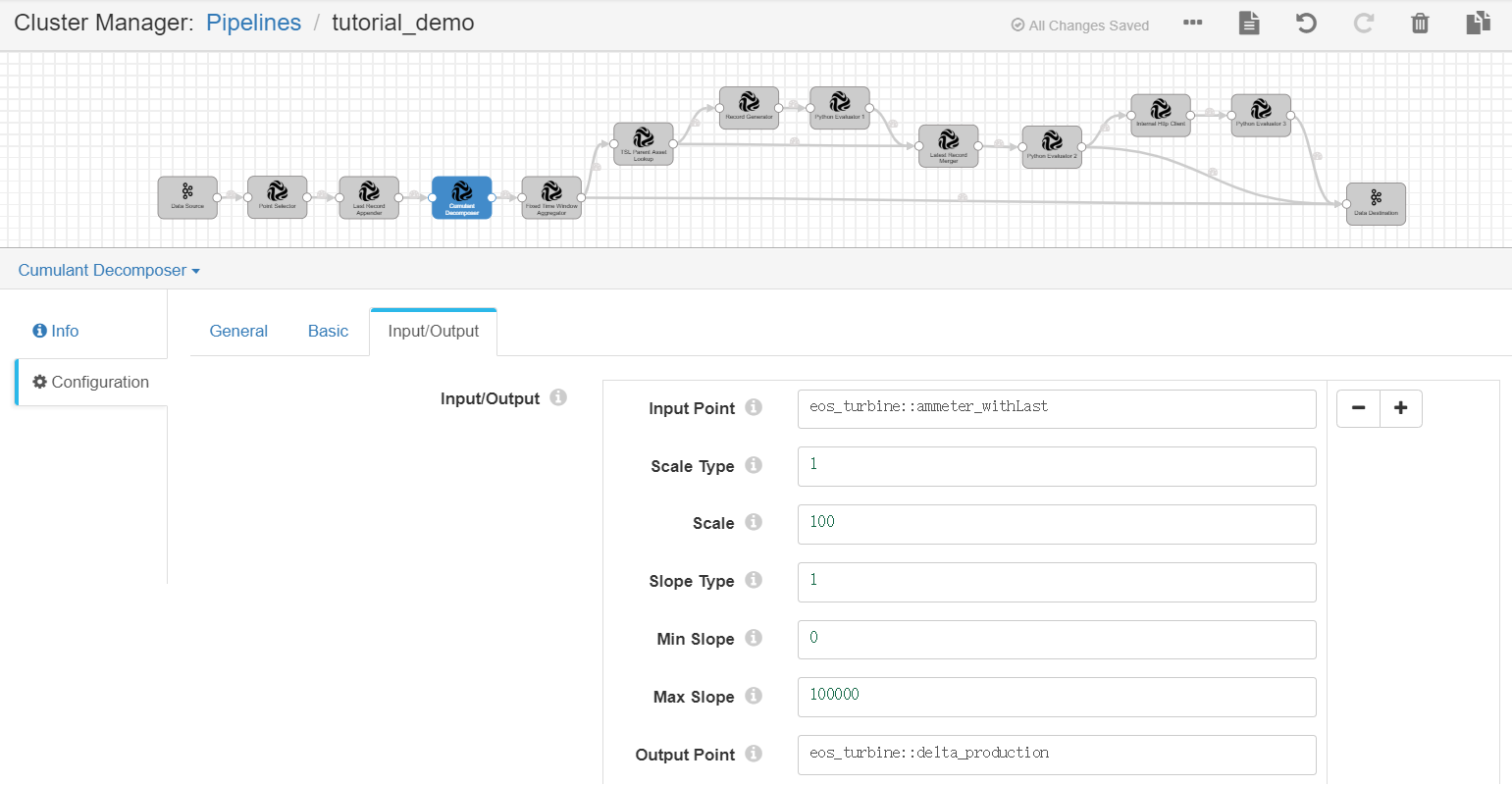
Cumulant Decomposer¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::ammeter_withLast |
Receives the current and last record of wind turbine energy production data as input. |
Scale Type |
1 |
Uses the fixed scale type for the electric energy meter. |
Scale |
100 |
Specifies the scale value of the electric energy meter. |
Slope Type |
1 |
Uses the fixed slope threshold. |
Min / Max Slope |
[0,100000] |
Specifies the lower and upper limits of the slope threshold. |
Output Point |
eos_turbine::delta_production |
Receives the output result, which contains the calculated energy production data of the wind turbines in the time interval. |
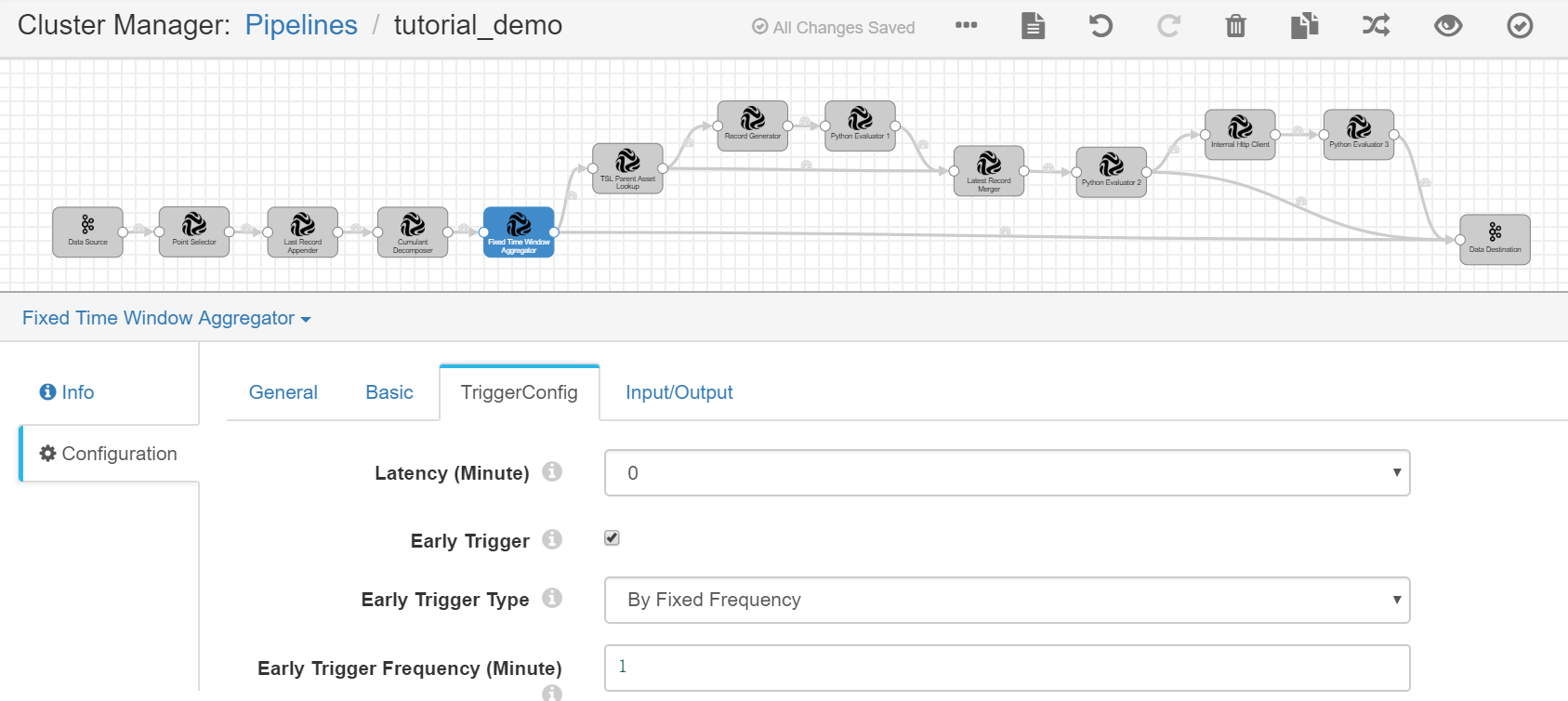
Fixed Time Window Aggregator¶
Complete the configuration of the TriggerConfig tab with the following.
Field |
Value |
Description |
|---|---|---|
Latency (Minute) |
0 |
Disables the data latency setting. |
Early Trigger |
Enable |
Enables the early output of intermediate results before the time window is closed. |
Early Trigger Type |
By Fixed Frequency |
Generates the early output of intermediate results by the fixed frequency. |
Early Trigger Frequency (Minute) |
1 |
Generates the early output by a 1-minute frequency. |
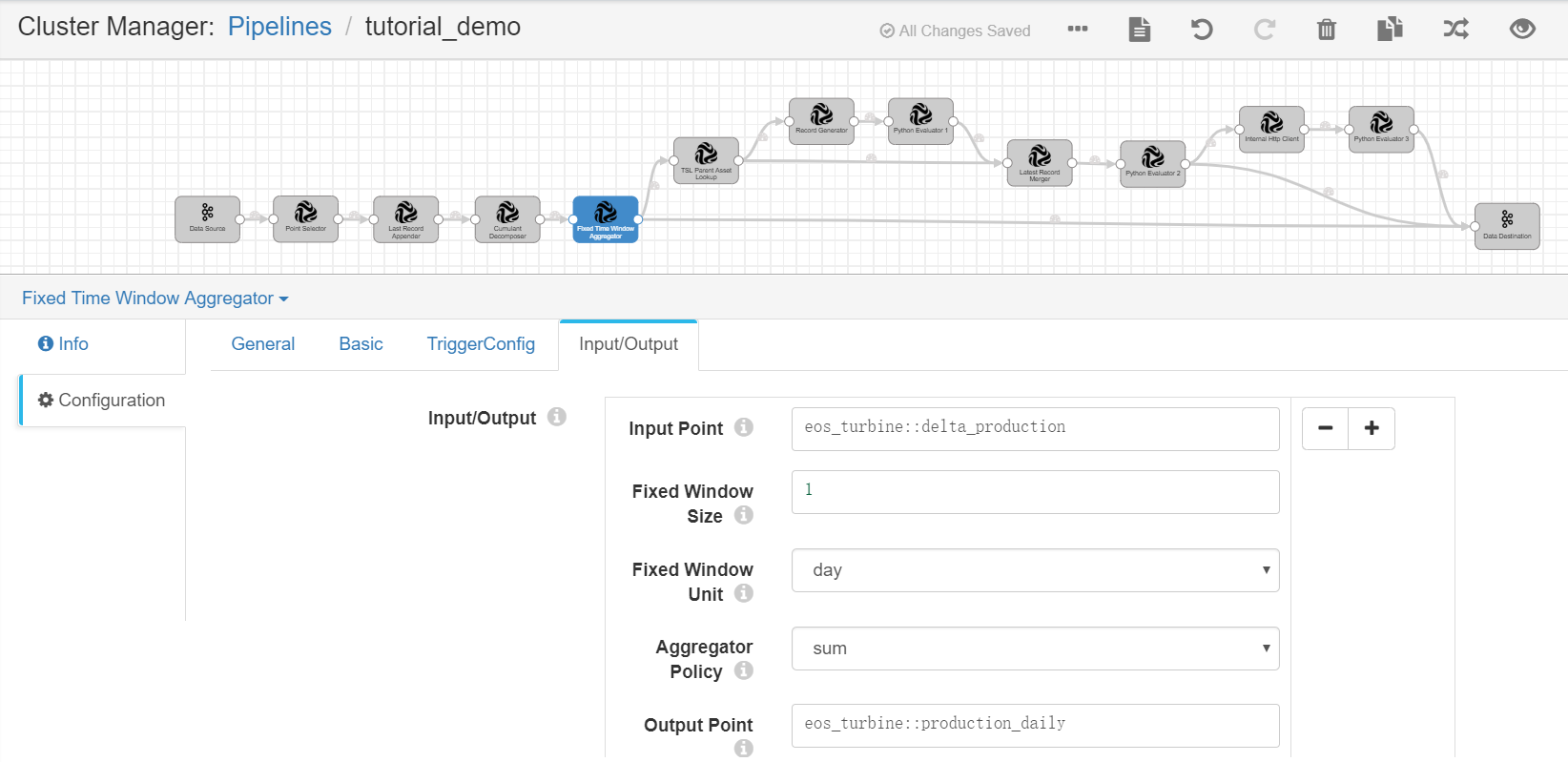
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::delta_production |
Receives the calculated energy production data of wind turbines in all time intervals as input. |
Fixed Window Size |
1 |
Specifies the duration for the fixed time window. |
Fixed Window Unit |
day |
Selects the unit for the fixed time window. For this tutorial, we will calculate the daily energy production data of the wind turbines. |
Aggregator Policy |
sum |
Sums up the energy production data of the wind turbines for all the time intervals in 1 day. |
Output Point |
eos_turbine::production_daily |
Receives the output result, which contains the calculated daily energy production data of the wind turbines. The output results will be used for further calculation and sent to Kafka as well. |
TSL Parent Asset Lookup¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::production_daily |
Receives the calculated daily energy production data of the wind turbines as input. |
Output Point |
eos_turbine::production_daily_withparent |
Receives the output result, which contains the calculated daily energy production data of the wind turbines and information of the wind farm. |
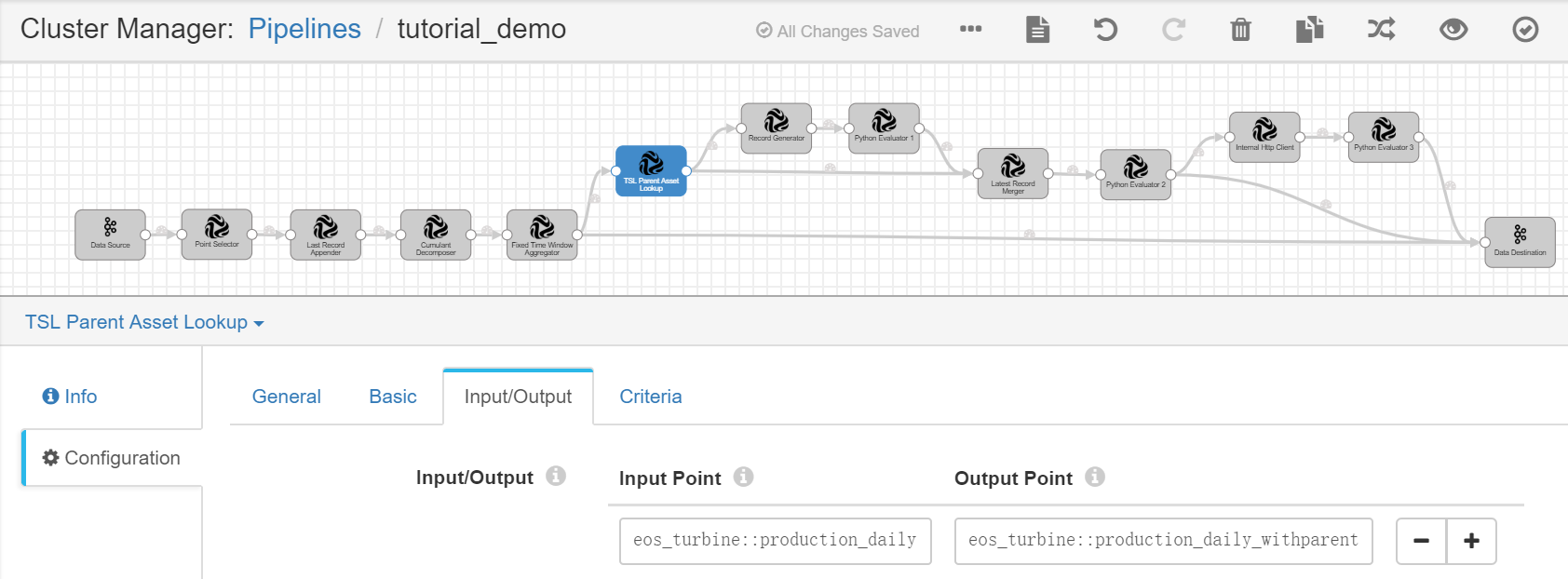
Complete the configuration of the Criteria tab with the following.
Field |
Value |
Description |
|---|---|---|
Tree Tag |
eos_tree::true |
Specifies the tag of the eos_tree asset tree that is created in Unit 1 . |
Attribute |
All |
Queries the wind farm metadata by all asset attribute keys. |
Tag |
None |
Does not query parent asset metadata by asset tags. |
Extra |
None |
Does not query parent asset metadata by extra information. |
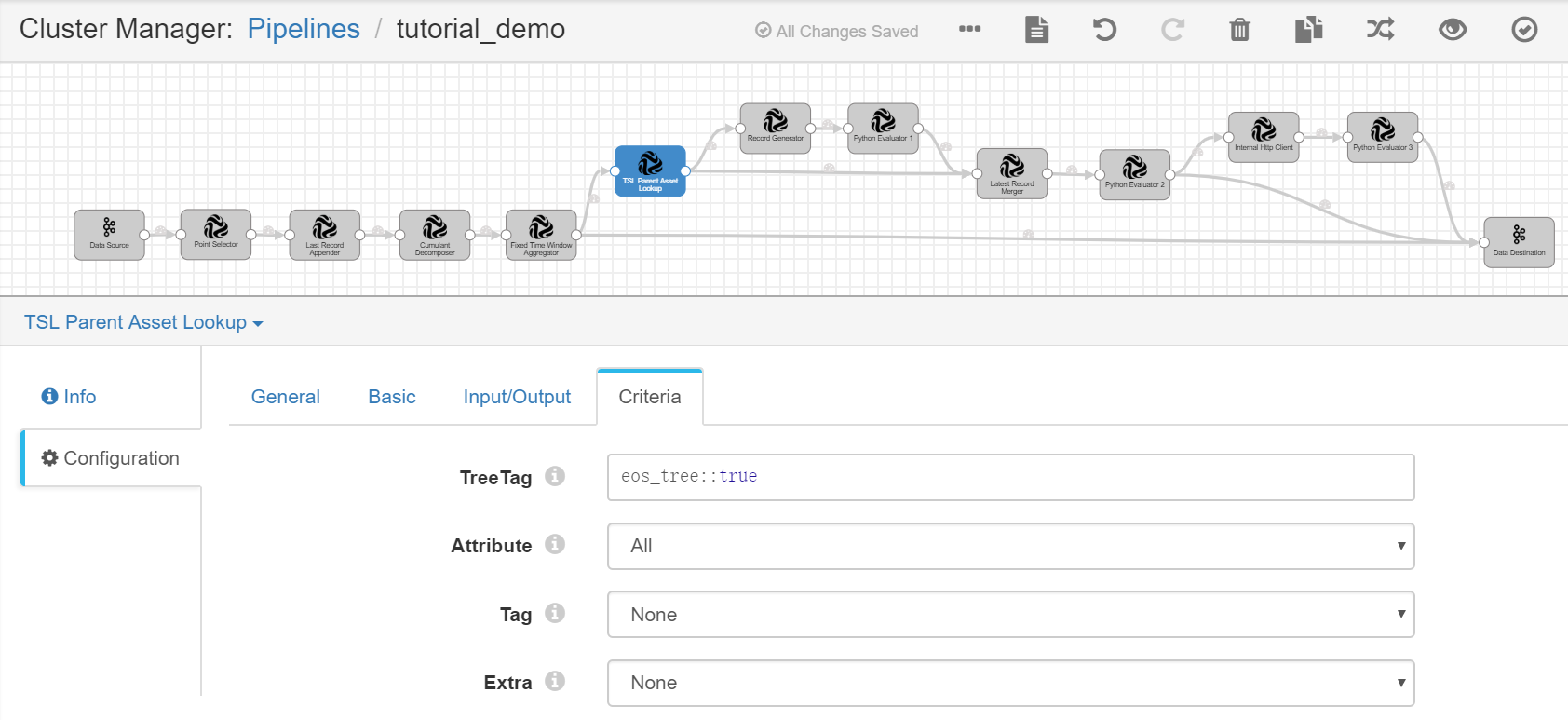
Record Generator¶
Complete the configuration of the Basic tab with the following.
Field |
Value |
Description |
|---|---|---|
Query Frequency |
1 Minute |
Generates new records by a 1-minute frequency. |
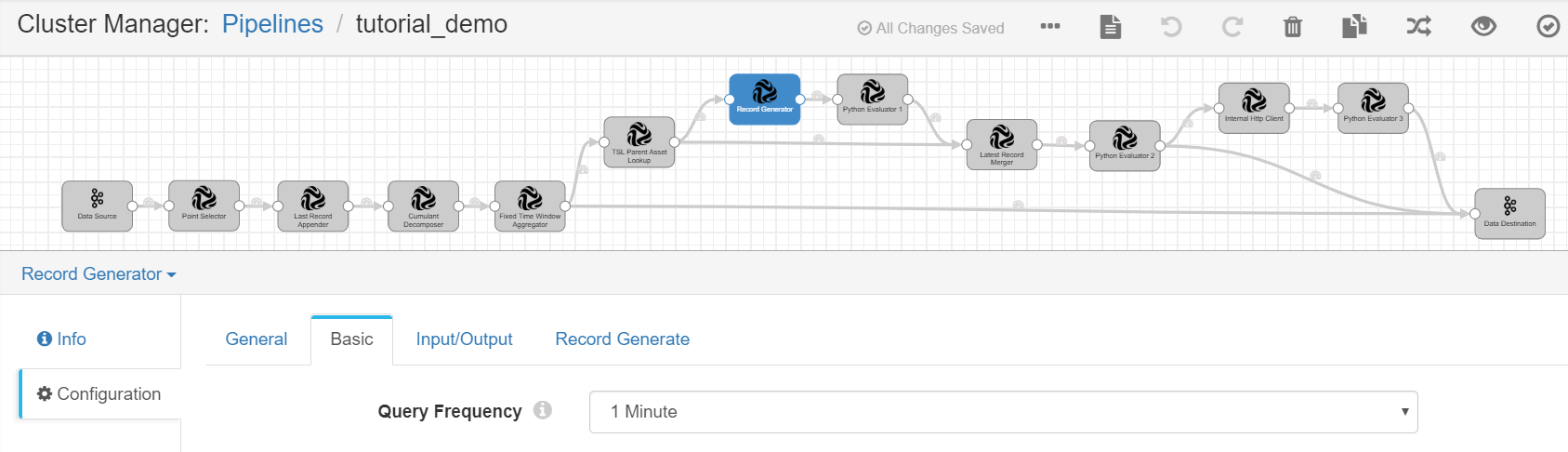
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Generate Type |
ByModelIDs |
Generates new records by model IDs. |
Output |
eos_site::production_day_trigger |
Receives the output result, which contains the calculated daily energy production data of the wind turbines and the generated data record for triggering the calculation of the wind farm energy production data. |
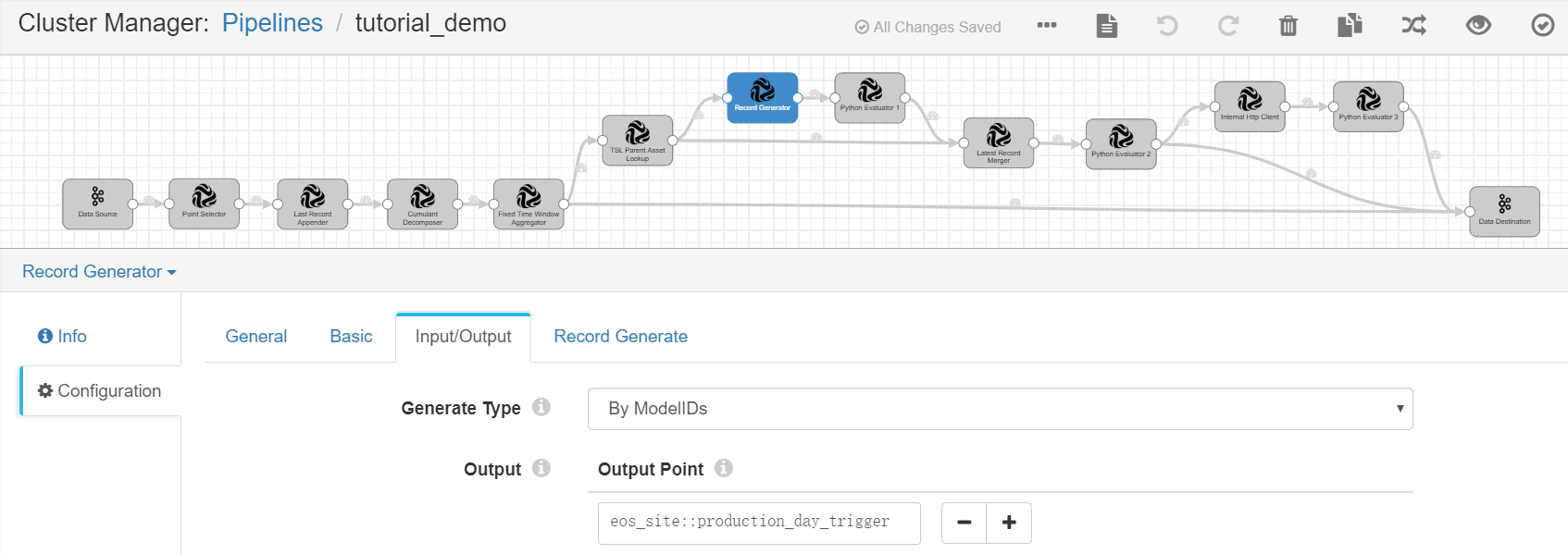
Complete the configuration of the Record Generate tab with the following.
Field |
Value |
Description |
|---|---|---|
Generate CommMethod |
Generate New Point |
Creates a point and generates data for the point by the specified methods. |
StartTime |
2019-08-26T00:00:00+08:00 |
Specifies the timestamp for the start time of the new point. |
Time Interval |
1 Minute |
Specifies the time interval for generating the new point data. |
Value Generator |
Quickly Random Number(Double) |
Randomly generates the point data. |
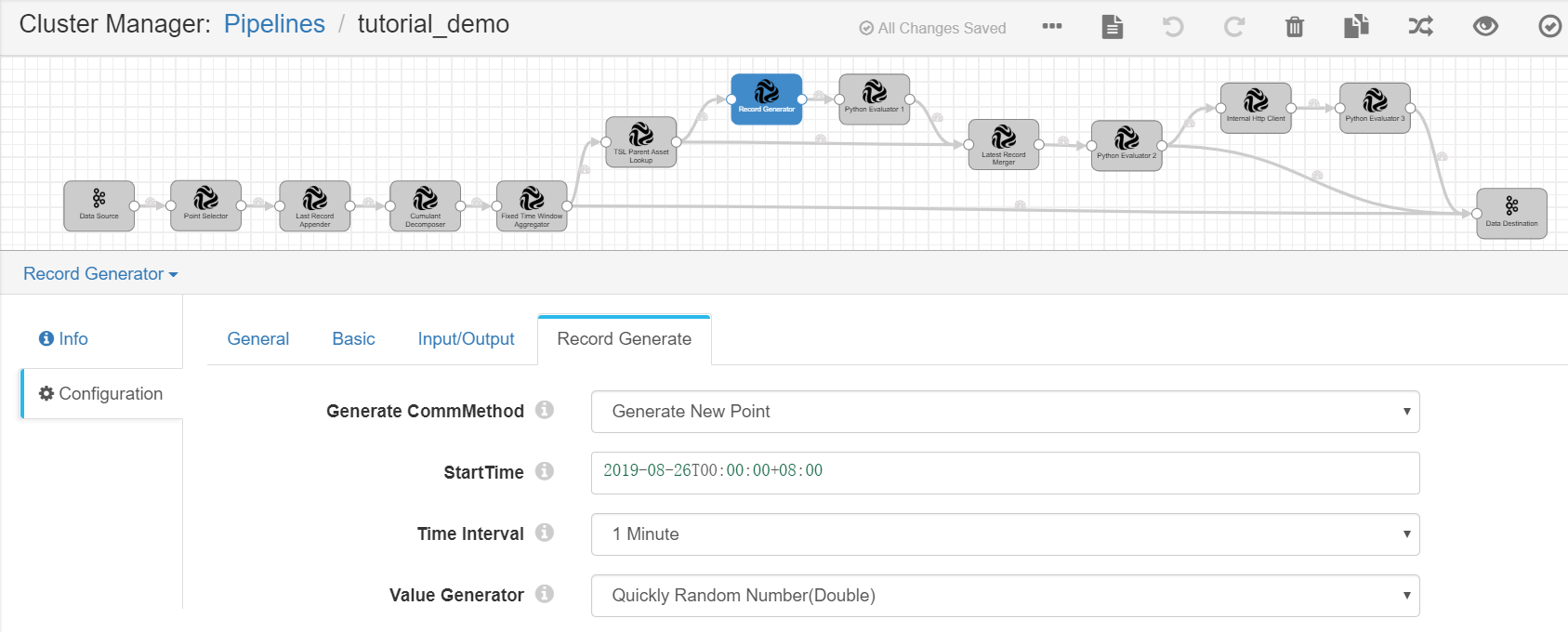
Python Evaluator 1¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_site::production_day_trigger |
Receives the calculated daily energy production data of the wind turbines and the generated data record for triggering calculation of wind farm energy production data as input. |
Output Point |
eos_site::production_day_trigger_withtag |
Receives the output result, which contains the calculated daily energy production data of the wind turbines and the triggering points appended with the wind farm information and tags. |
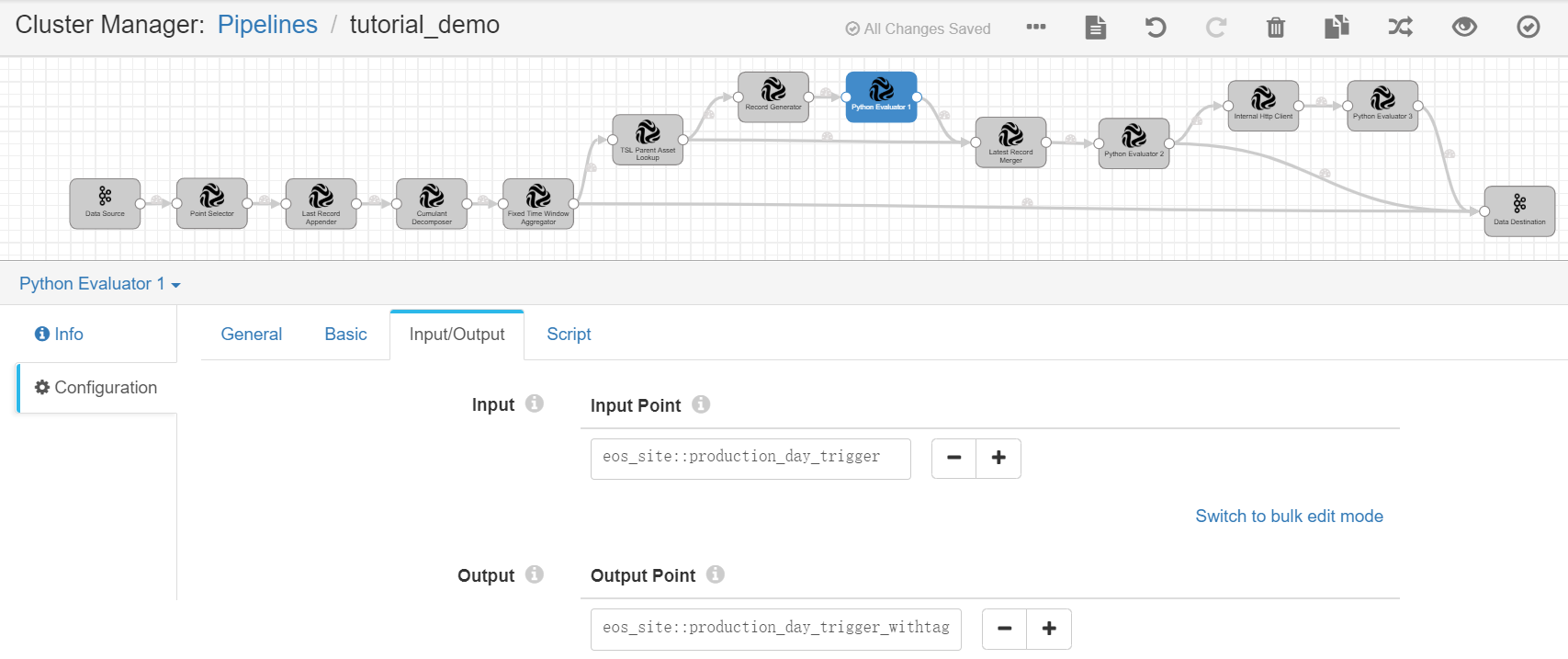
Under the Script tab, copy and paste the following script in the Python Script field for appending the wind farm information to the generated triggering point and tagging the triggering point.
import time
for record in records:
try:
parentRecord = {'id':record.value['assetId']}
record.value['attr']=dict()
record.value['attr']['tslParentLookup']=[]
record.value['attr']['tslParentLookup'].append (parentRecord)
record.value['attr']['triggerTag'] = True
record.value['time'] = long(round(time.time() * 1000))
record.value['pointId']='production_day_trigger_withtag'
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))
Latest Record Merger¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_turbine::production_daily_withparent |
Receives the calculated daily energy production data of the wind turbines and the wind farm information as input. |
Input Point |
eos_site::production_day_trigger_withtag |
Receives the calculated daily energy production data of the wind turbines and the triggering points appended with the wind farm information and tags as input. Specifies this point as the processing trigger. |
Output Point |
eos_site::turbine_merger |
Receives the output result, which contains the merged data records of energy production data of the wind turbines according to the wind farm attribute. |
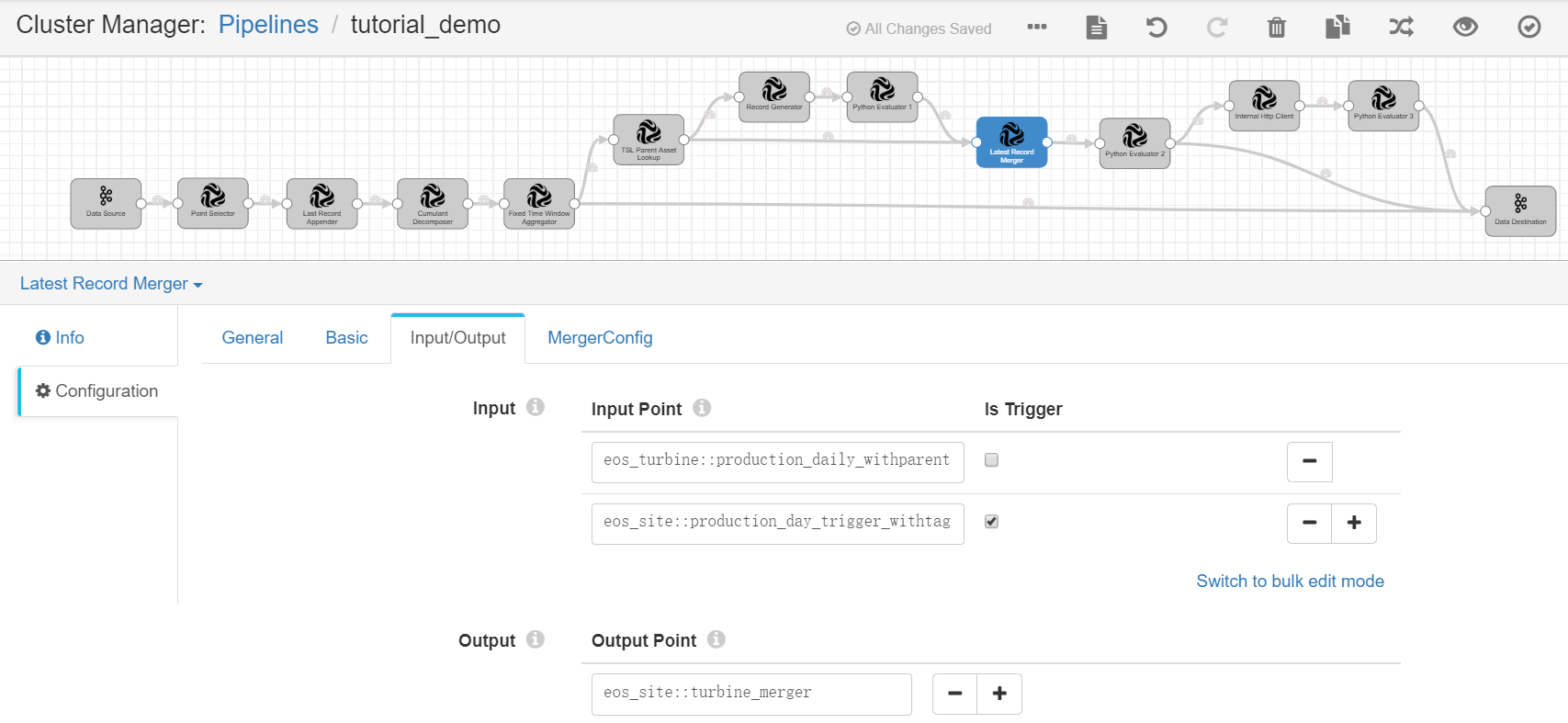
Complete the configuration of the MergeConfig tab with the following.
Field |
Value |
Description |
|---|---|---|
Merged By Expression |
${record:value(‘/attr/tslParentLookup[0]/id’)} |
Specifies the expression for generating tags that are used to merge the latest records. |
Cache Expire Time (Minute) |
1440 |
Specifies the cache expiring time if the tags are not updated. |
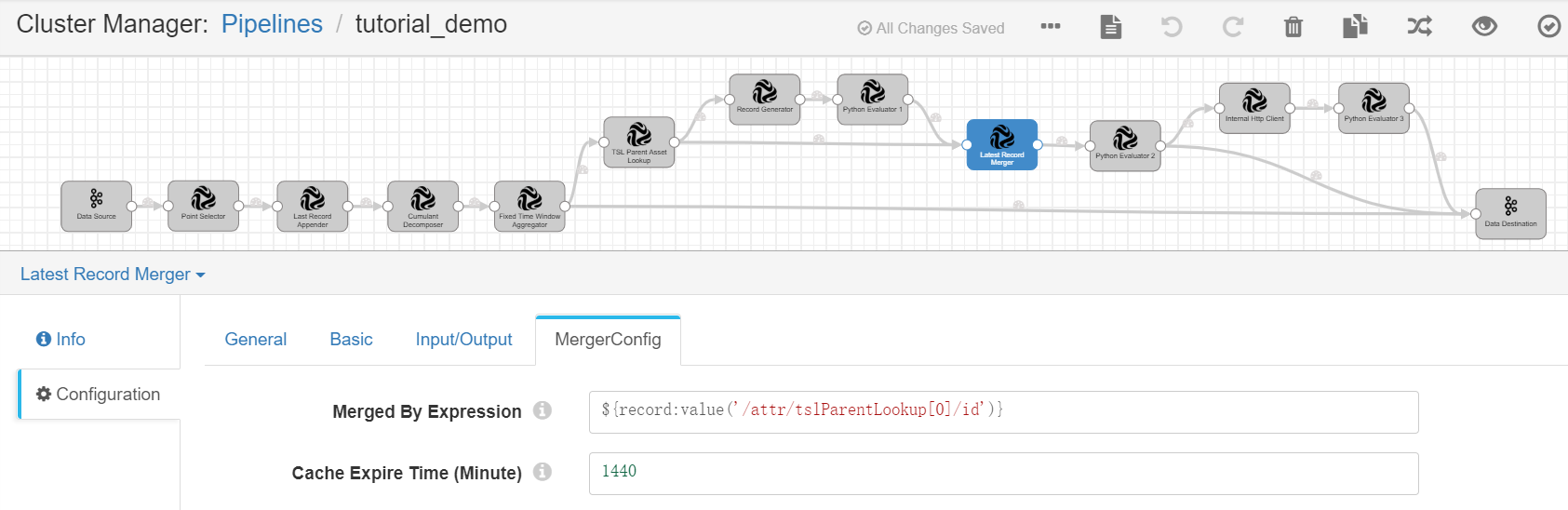
Python Evaluator 2¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_site::turbine_merger |
Receives the merged data records of the energy production data of wind turbines according to the wind farm attribute as input. |
Output Point |
eos_site::production_day |
Receives the output result, which contains the calculated daily energy production data of the wind farms. The output results will be used for further calculation and sent to Kafka as well. |
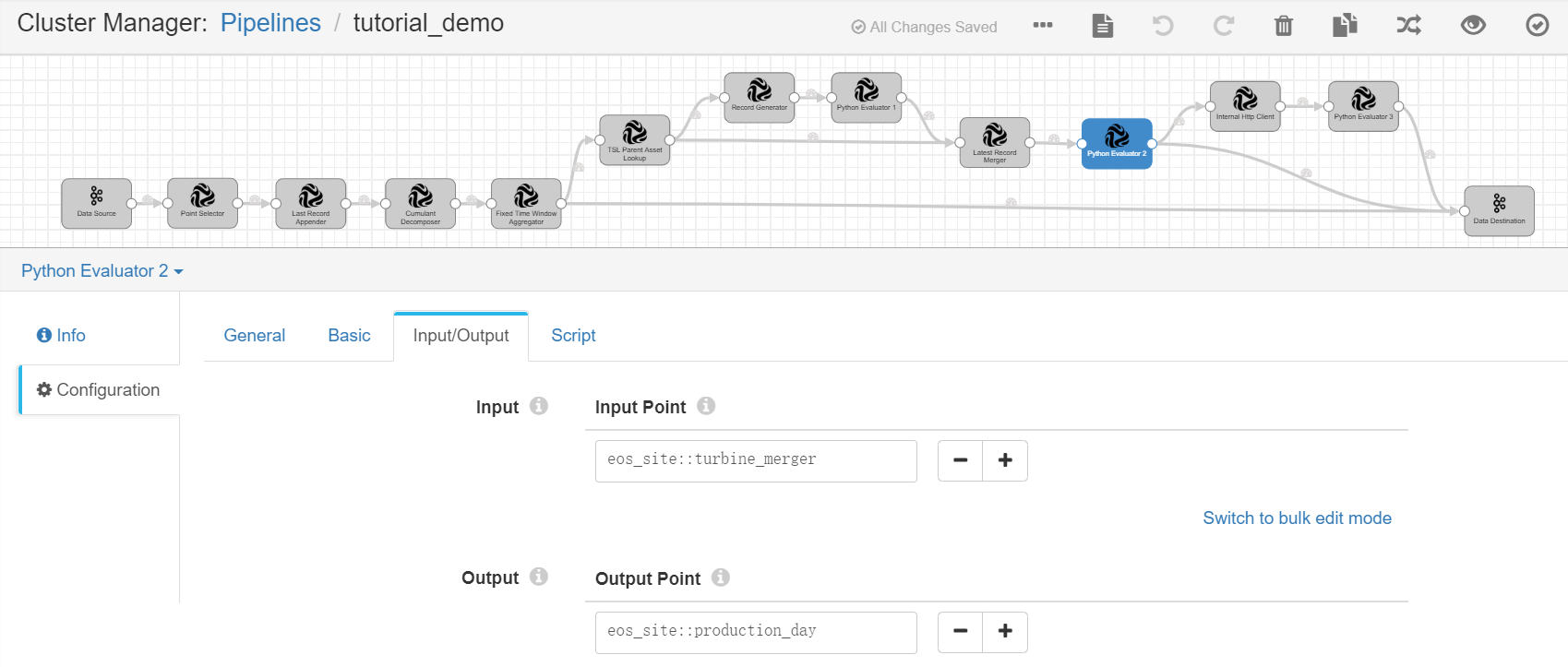
Under the Script tab, copy and paste the following script in the Python Script field for calculating the daily energy production data of the wind farms.
from decimal import Decimal
for record in records:
try:
mergedRecords = record.value['attr']['latestRecordMerger']['mergedRecords']
triggerRecords = []
calculateRecords = []
for mergedRecord in mergedRecords:
isTriggerPoint = mergedRecord['attr'].has_key('triggerTag') and mergedRecord['attr']['triggerTag']
if isTriggerPoint:
triggerRecords.append(mergedRecord)
else:
calculateRecords.append(mergedRecord)
if len(triggerRecords) == 1:
v_sum = '0.0'
for calculateRecord in calculateRecords:
v_sum = str(Decimal(str(calculateRecord['value'])) + Decimal(v_sum))
record.value['value'] = float(v_sum)
record.value['time'] = triggerRecords[0]['time']/60000*60000
record.value['assetId'] = triggerRecords[0]['assetId']
record.value['modelId'] = triggerRecords[0]['modelId']
record.value['modelIdPath'] = triggerRecords[0]['modelIdPath']
record.value['pointId'] = 'production_day'
record.value['attr'] = dict()
output.write(record)
else:
error.write(record, "invalid record")
except Exception as e:
# Send record to error
error.write(record, str(e))
Internal HTTP Client¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_site::production_day |
Receives the daily energy production data of the wind farms as input. |
Output Point |
eos_site::with_carbonReduction |
Receives the output result, which contains the daily energy production data of the wind farms and the queried carbon reduction parameter. |
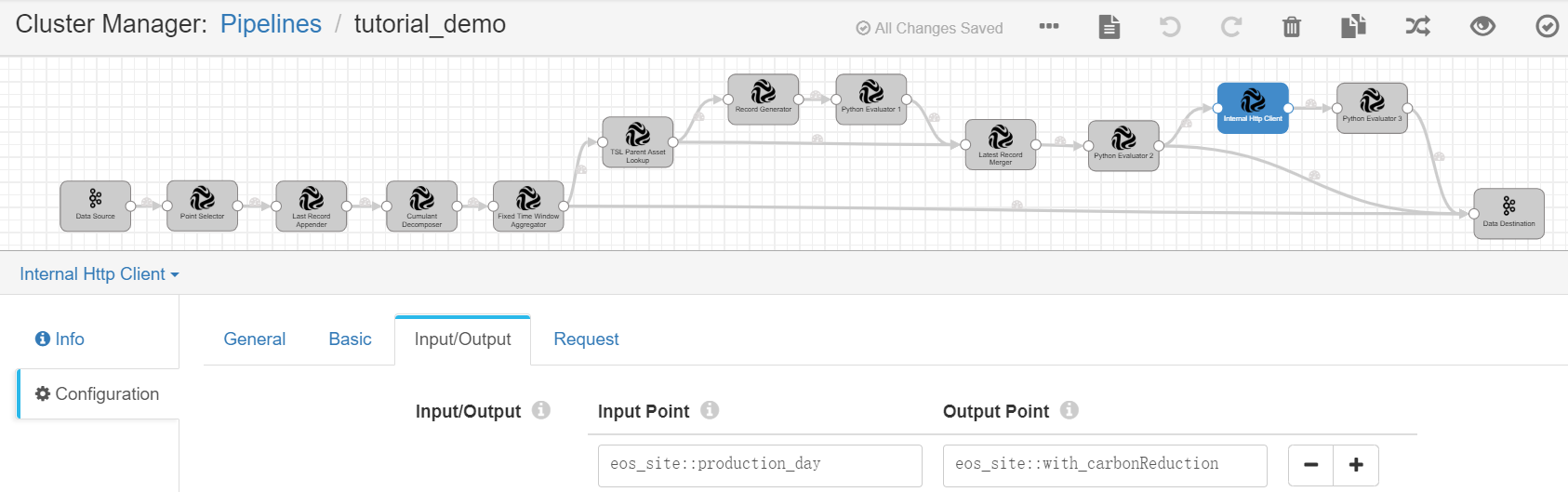
Complete the configuration of the Request tab with the following.
Field |
Value |
Description |
|---|---|---|
Request Method |
Get |
Selects the API request method. For the Get Asset API, select the Get method. |
Request URL |
https://{enos-api-gateway}/asset-service/v2.1/assets?action=get |
Specifies the API request URL. To get the API request URL, go to EnOS Management Console > EnOS API. |
Param Key |
assetId |
Specifies the following values for the assetId parameter:
|
Param Key |
orgId |
Specifies the following values for the orgId parameter:
|
Access Key |
access_key |
Specifies the access key of the application which is used for API request authentication. For detailed information, see Registering and Managing Applications . |
Secret Key |
secret_key |
Specifies the secret key of the application. |
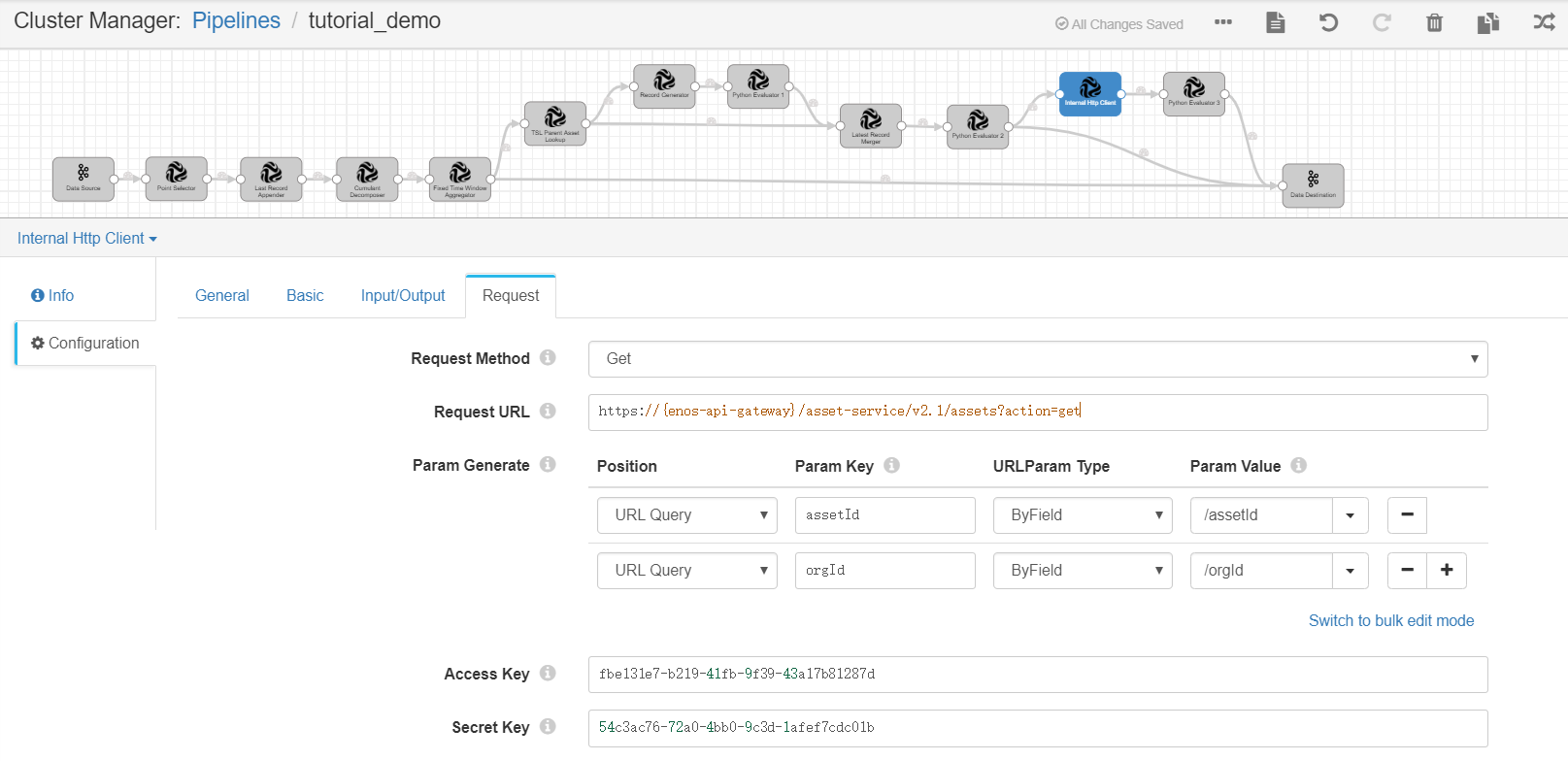
Python Evaluator 3¶
Complete the configuration of the Input/Output tab with the following.
Field |
Value |
Description |
|---|---|---|
Input Point |
eos_site::with_carbonReduction |
Receives the daily energy production data of the wind farms and the queried carbon reduction parameter as input. |
Output Point |
eos_site::carbon.reduction.daily |
Receives the output result, which contains the calculated daily carbon reduction data of the wind farms. The output results will be sent to Kafka. |
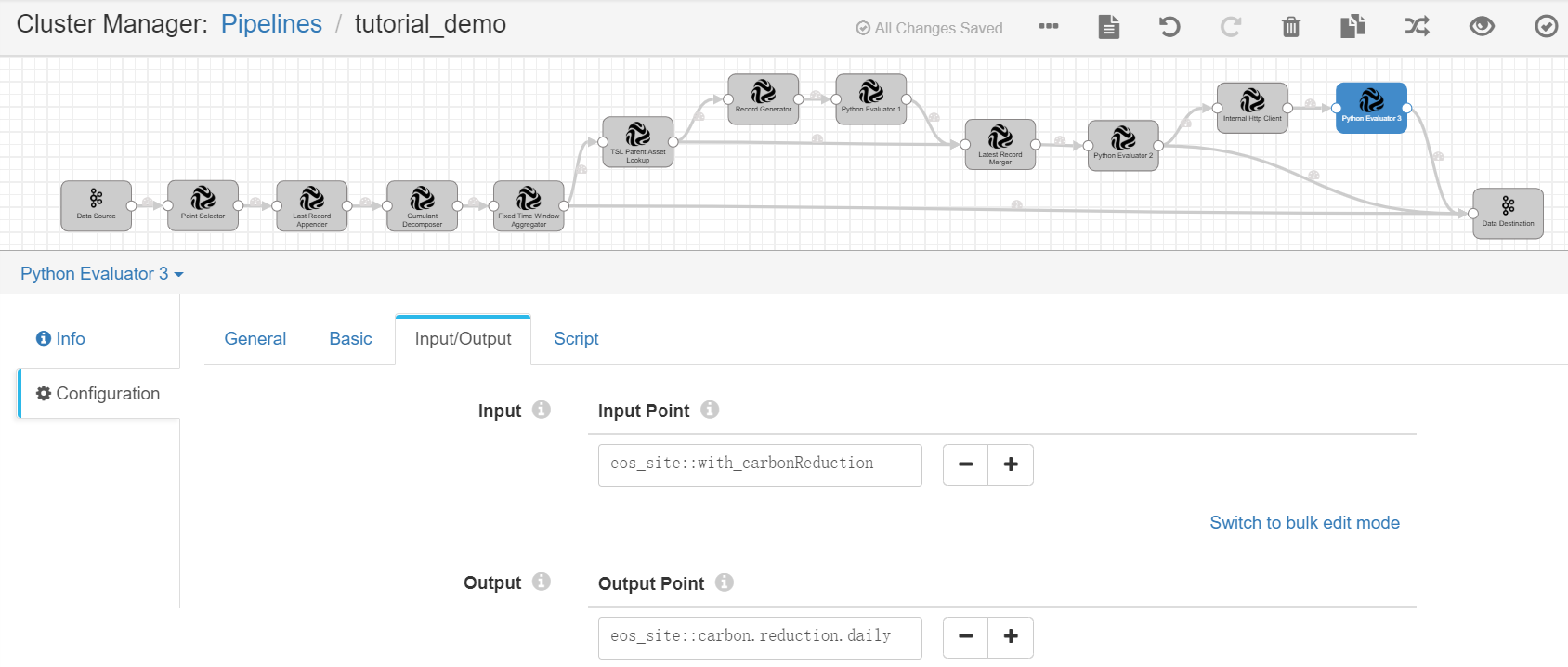
Under the Script tab, copy and paste the following script in the Python Script field for calculating the daily carbon reduction data of the wind farms.
import json
for record in records:
try:
record.value['pointId'] = 'carbon.reduction.daily'
production = record.value['value']
json_response = json.loads(record.value['attr']['httpClient']['response'])
carbon= json_response['data']['attributes']['carbon.reduction.param']
record.value['value']= production/carbon
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))
Validating and running the pipeline¶
When the configuration of the operators is completed, we can now validate the configuration and start running the pipeline.
Click the Validate icon
 in the tool bar to verify the configuration for all the operators.
in the tool bar to verify the configuration for all the operators.
If the validation fails, update the configuration of the operators accordingly.
If the validation is successful, click the Start icon
 in the tool bar to start running the pipeline. It may take about 5 minutes for the pipeline to start up.
in the tool bar to start running the pipeline. It may take about 5 minutes for the pipeline to start up.When the pipeline is running, you can check the data processing result in the Monitoring section.
Select any stage in the pipeline to check the input data and output data of the stage.