Developing with StreamSets Calculators¶
The EnOS Stream Processing Service provides a set of underlying packaged StreamSets calculators for developers to develop customized stream data processing jobs to meet the requirements of various business scenarios.
Overview¶
StreamSets provides a user-friendly drag-and-drop UI for designing data processing jobs (pipelines). You can quickly configure pipelines by adding calculators (stages) to the pipeline, thus completing data ingestion, filtering, processing, and storage tasks without any programming.
A data processing pipeline usually consists of multiple stages that are connected by arrows that define the data stream, though which the data sequentially flows. Each stage represents a read-and-write or processing operation to the data. This kind of process forms a stream data processing job. A pipeline can include the following stages.
Origin
The stage that specifies the data source and passes the output data to later stages, such as the Kafka Consumer stage.
Processor
The stage for data conversion, where the input data is normalized or changed (such as data filtering, transforming, calculation, etc.).
Destination
The stage for storing the processed data in the target storage or sending data for further processing.
Designing a Pipeline¶
EnOS provides a pipeline configuration template for designing StreamSets pipelines. You can import it to speed up the design process.
Click
Download the StreamSets pipeline configuration templateand save thestreamsets_pipeline_demo.jsonfile to a local directory.Log in to the EnOS Management Console, select Stream Processing > Streamsets, click the triangle beside the Create New Pipeline button, and select Import Pipeline.
On the Import Pipeline window, enter a pipeline title and description, click Browse …, navigate to and select the configuration template file, and click Import.
Set the yarn queue for the new pipeline. Click the Cluster tab, set the value of the
spark.yarn.queuefield asroot.streaming_{orgId}, in whichorgIdis the organization ID (can be retrieved on the IAM > Organization Profile page on EnOS Management Console).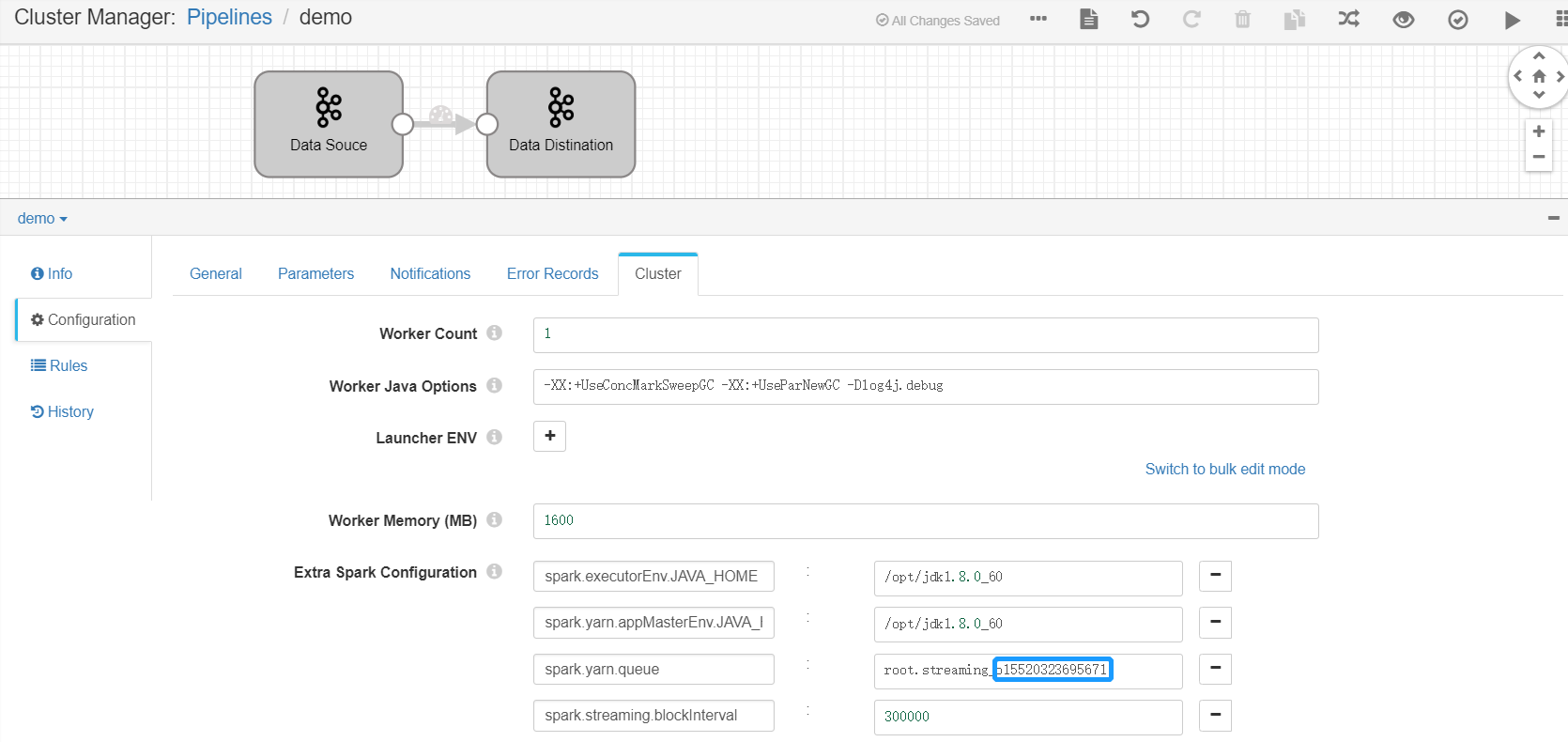
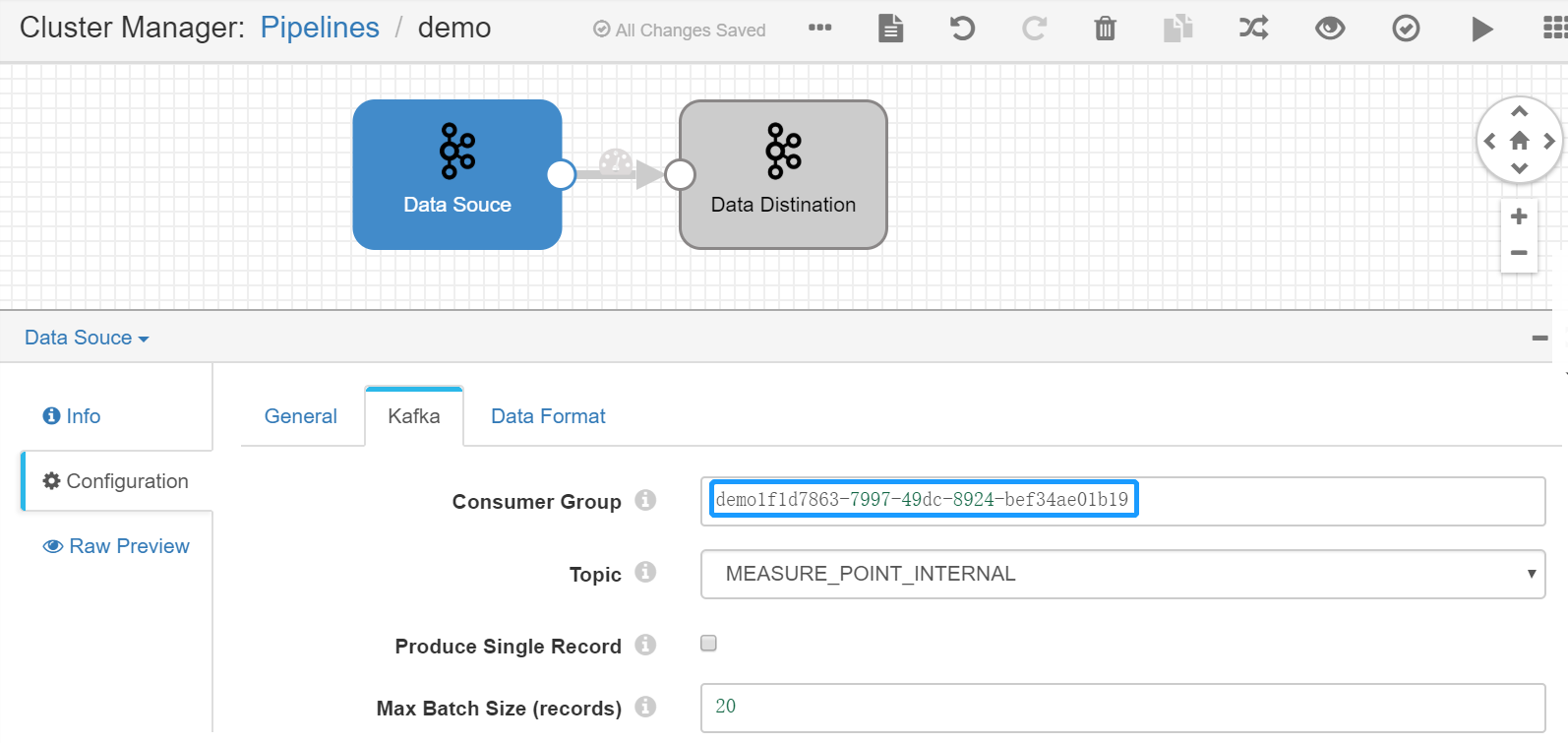
Set the Kafka Consumer Group. Select the Data Source Stage, click the Kafka tab, and set the value of the Consumer Group parameter (which must be unique within the organization).
Select a stage you want to use (like the Point Selector) from the Stage Library in the upper right corner of the page to add it to the pipeline canvas.

Delete the arrow connecting the Data Source and Data Distination stages and connect the Data Source stage to the new stage by clicking the output point of the Data Source stage and dragging it to the input point of the new stage. Do the same to connect the new stage to the Data Distination stage to complete adding the new stage to the pipeline. Select the new stage and complete the parameter configuration.

Repeat steps 6 and 7 to add more stages to the pipeline and complete the parameter configuration of the stages.
Click the Validate icon
 in the tool bar to check the parameter configuration of the stages. If the validation fails, update the configuration accordingly.
in the tool bar to check the parameter configuration of the stages. If the validation fails, update the configuration accordingly.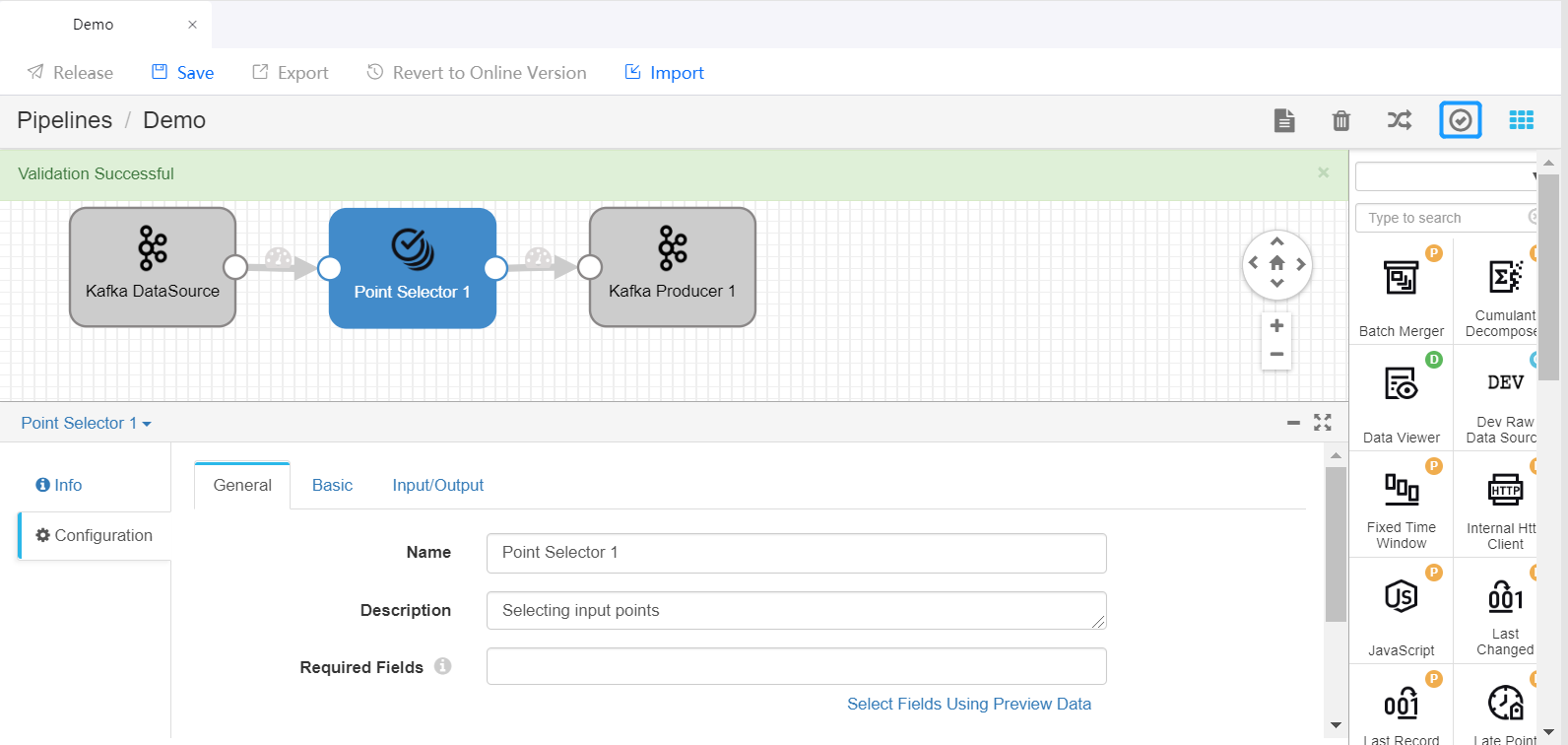
For more information about designing StreamSets pipelines, see StreamSets User Guide.
Previewing and Running the Pipeline¶
If the validation is successful, you can preview and run the pipeline.
Click the Preview icon
 in the tool bar, enter the preview configuration, and click Run Preview.
in the tool bar, enter the preview configuration, and click Run Preview.Select any stage in the pipeline to check the input data and output data of the stage.
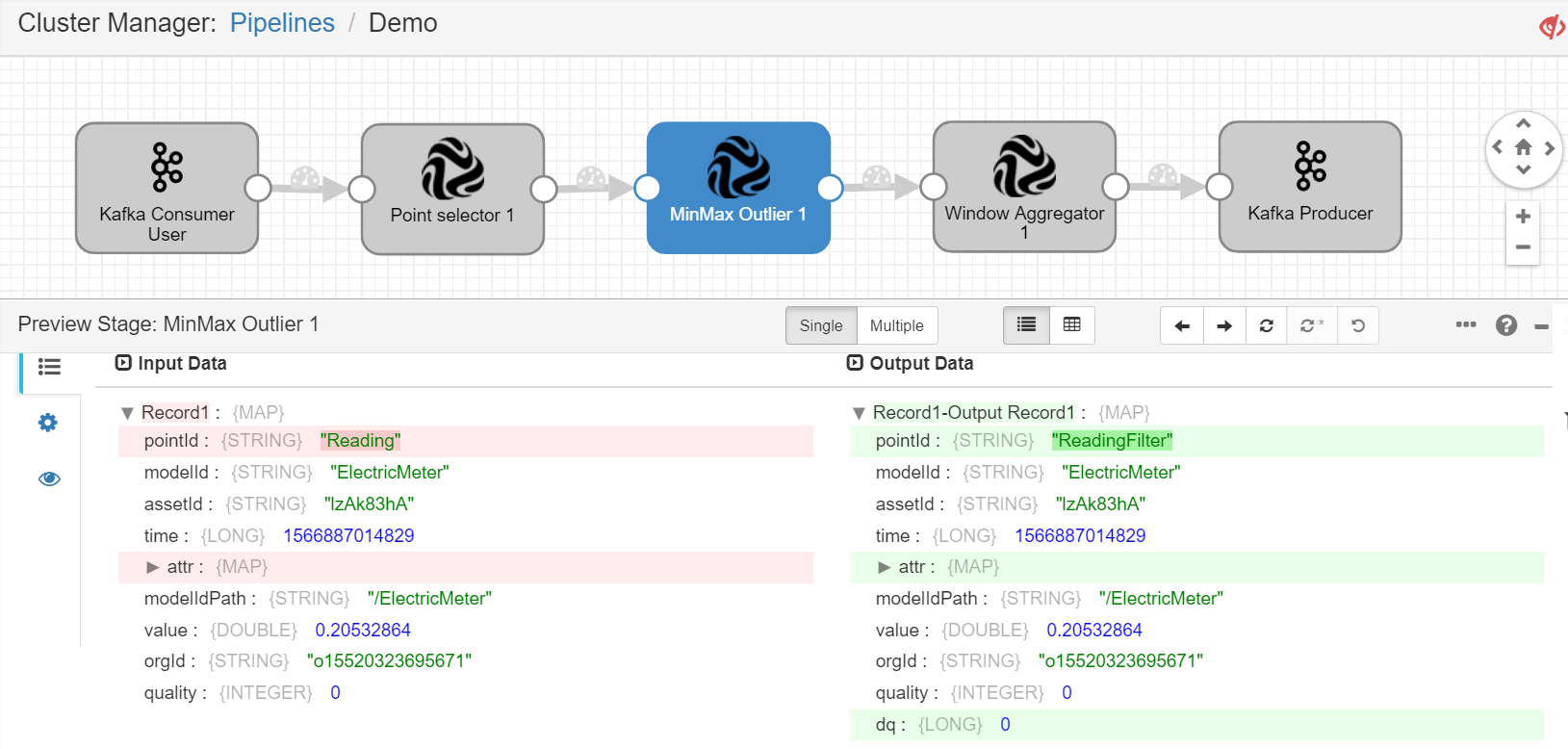
If the preview runs correctly as designed, close the preview, and click the Start icon
 in the tool bar to start running the pipeline.
in the tool bar to start running the pipeline.When the pipeline is running, you can check the data processing result in the Monitoring section.
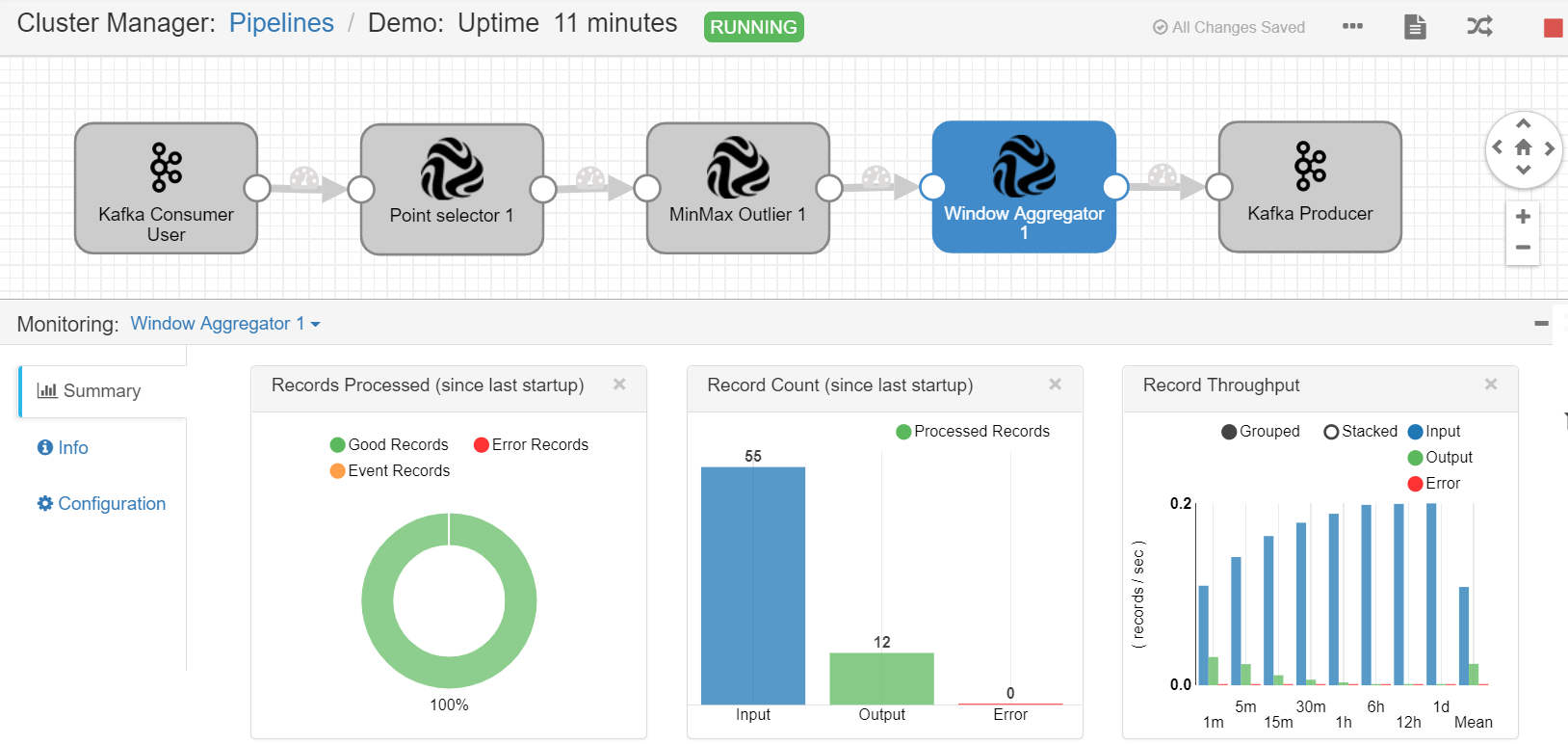
StreamSets Operator Documentation¶
For detailed information about the function, parameter configuration, and output of the available operators, see the StreamSets Calculator Documentation.
Tutorial¶
To learn how to develop a stream data processing pipeline for a more complex business scenario, see Developing with StreamSets Operators.