Python Evaluator¶
This stage supports the running of native Python scripts to meet the requirements of custom business logic.
Configuration¶
The configuration tabs for this stage are General, Basic, Input/Output, and Script.
General¶
Name |
Required? |
Description |
|---|---|---|
Name |
Yes |
The name of the stage. |
Description |
No |
The description of the stage. |
Stage Library |
Yes |
The streaming operator library to which the stage belongs. |
Required Fields |
No |
The fields that the data records must contain. If the specified fields are not included, the record will be filtered out. |
Preconditions |
No |
The conditions that must be satisfied by the data records. Records that do not meet the conditions will be filtered out. For example, |
On Record Error |
Yes |
The processing method for error data.
|
Basic¶
Name |
Required? |
Description |
|---|---|---|
Lineage Mapping |
Yes |
Select the mapping between the input and output points.
|
Quality Filter |
No |
Filter the data according to the data quality. Only records that meet the quality conditions will be processed by this stage. |
Input/Output¶
Name |
Required? |
Description |
|---|---|---|
Input Point |
Yes |
Specify the input point of the records, using the format {modelId}::{pointId}. The modelIdPath and pointId of the input data must match with those of the input point. |
Output Point |
No |
Specify the output point of the records, using the format {modelId}::{pointId}. The modelIdPath and pointId of the output data processed by the Python script must match with those of the output point. |
Script¶
Name |
Required? |
Description |
|---|---|---|
Python Script |
Yes |
Enter the customized Python script, where records represents the input data that has been filtered by the quality conditions. |
Output Results¶
After running the customized script, the output results of this stage are included in the attr struct.
Output Example¶
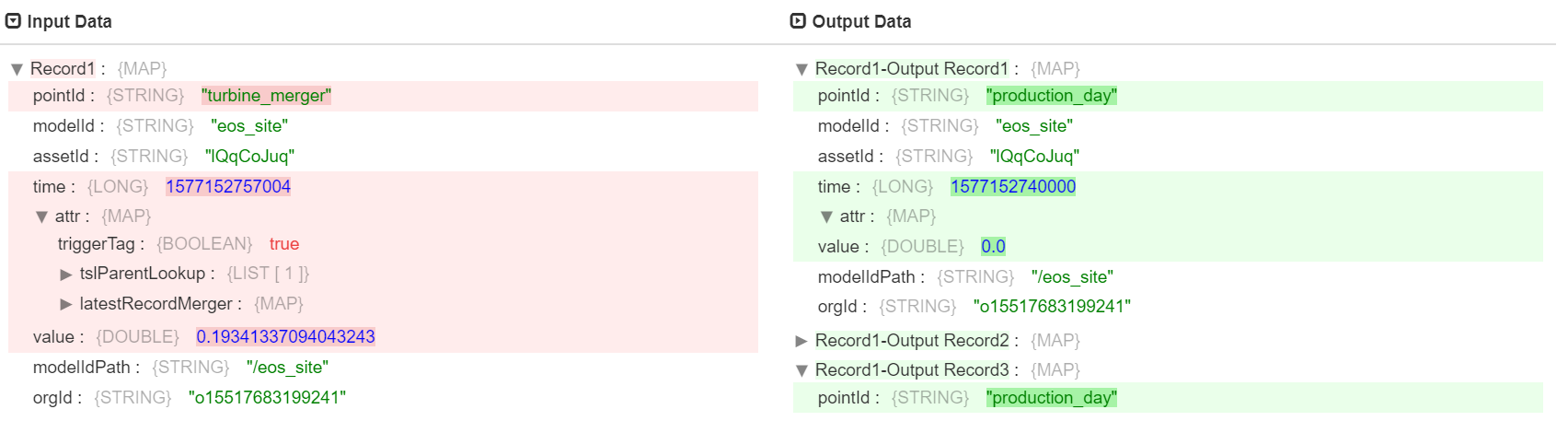
Python Script Development Guide¶
# Available constants:
They are to assign a type to a field with a value null.
NULL_BOOLEAN, NULL_CHAR, NULL_BYTE, NULL_SHORT, NULL_INTEGER, NULL_LONG
NULL_FLOATNULL_DOUBLE, NULL_DATE, NULL_DATETIME, NULL_TIME, NULL_DECIMAL
NULL_BYTE_ARRAY, NULL_STRING, NULL_LIST, NULL_MAP
# Available Objects:
records: an array of records to process, depending on Jython processor processing mode it may have 1 record or all the records in the batch.
state: a dict that is preserved between invocations of this script. Useful for caching bits of data e.g. counters.
log.<loglevel>(msg, obj...):
use instead of print to send log messages to the log4j log instead of stdout.
loglevel is any log4j level: e.g. info, error, warn, trace.
output.write(record): writes a record to processor output
error.write(record, message): sends a record to error
sdcFunctions.getFieldNull(Record, 'field path'): Receive a constant defined above to check if the field is typed field with value null
sdcFunctions.createRecord(String recordId): Creates a new record.
Pass a recordId to uniquely identify the record and include enough information to track down the record source.
sdcFunctions.createMap(boolean listMap): Create a map for use as a field in a record.
Pass True to this function to create a list map (ordered map)
sdcFunctions.createEvent(String type, int version): Creates a new event.
Create new empty event with standard headers.
sdcFunctions.toEvent(Record): Send event to event stream
Only events created with sdcFunctions.createEvent are supported.
sdcFunctions.isPreview(): Determine if pipeline is in preview mode.
Available Record Header Variables:
record.attributes: a map of record header attributes.
record.<header name>: get the value of 'header name'.
# Add additional module search paths:
import sys
sys.path.append('/some/other/dir/to/search')