流数据处理概述¶
基于Apache Spark™ Streaming,经过Envision定制和优化,EnOS™流数据处理服务具有高可扩展性、高吞吐量、和高容错性等优点。EnOS还致力于沉淀IoT领域的流处理常用算法,开发者可通过简单的模板配置,即可完成流数据处理任务的开发。此外,流数据处理服务沉淀了多套能源领域计算模板及通用算子,帮助数据开发者无需编码即可快速开发数据处理解决方案,大幅提升了数据开发效率,降低了开发门槛。
EnOS流数据处理服务的主要功能组成和架构,如下图所示:
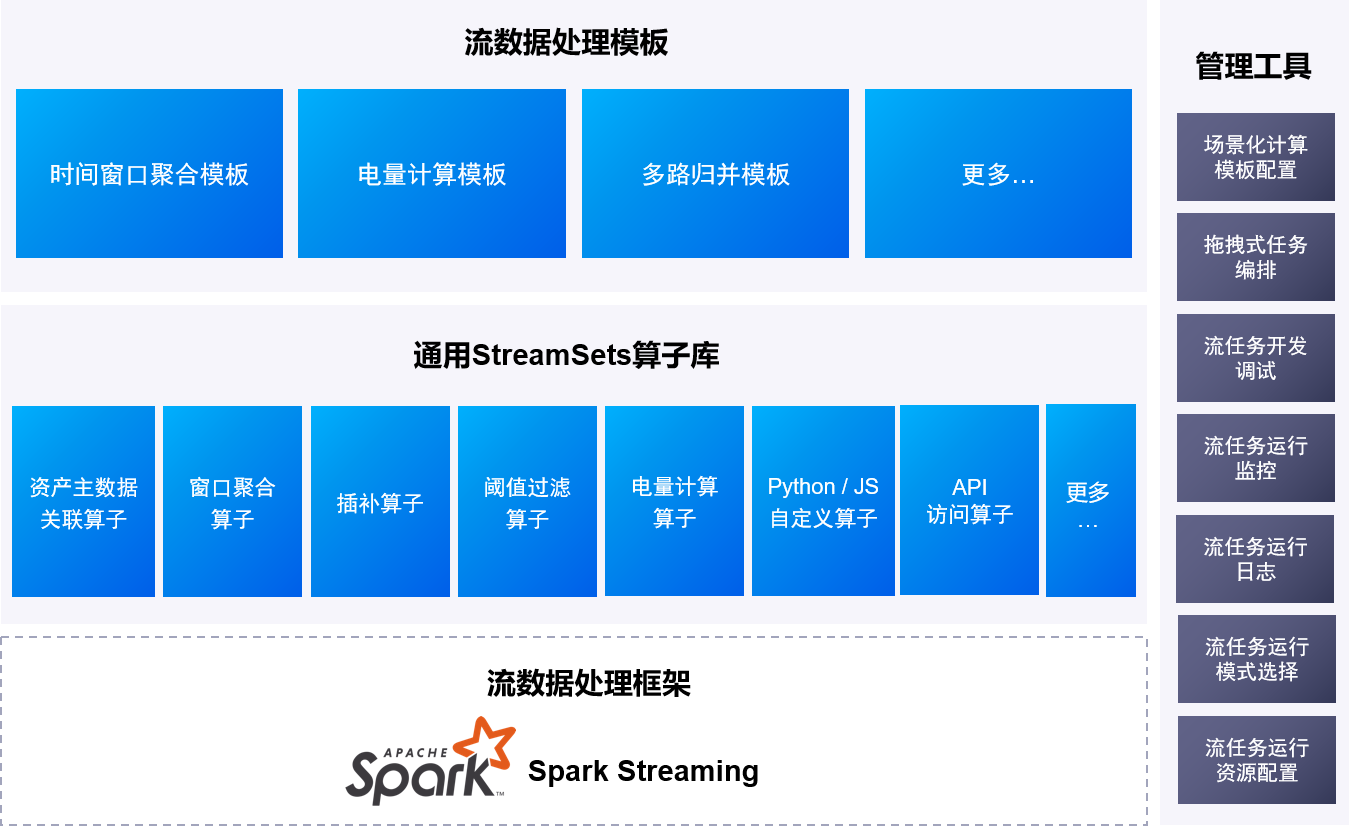
EnOS™流数据处理服务可以应用于如下场景:
资产原始数据的聚合计算
在大多数业务场景中,你可能需要过滤从设备接收到的原始数据,通过特定的算法对数据进行计算,并保存聚合计算后的数据以便作进一步分析。
设备状态计算
在某些业务场景中,你可能需要获取设备的状态参数以确认其状态。通过流数据处理,可维护设备和站点的状态 (系统将测量点值和设备连接状态更新为最新状态,如果设备测点停止上送数据,设备连接可能中断)。
定制化流数据处理
在某些业务场景中,你可能需要进行复杂的流数据计算。EnOS流数据处理服务提供一整套底层封装好的StreamSets算子,供开发者基于业务需求开发定制化的流数据处理任务。
流数据处理流程¶
EnOS流数据处理服务的流程如下:
原始数据处理
测点原始数据通过EnOS连接层发送到Kafka。流计算服务对接收到的测点信息进行分析。在处理之前,数据按指定的阈值进行过滤。超过阈值范围的数据将通过插值算法进行处理。
数据计算
经过阈值过滤之后的数据,由数据处理策略中定义的算法进行聚合计算。
输出计算结果
经流数据处理模块处理之后的数据会流入内存数据库(IMDB)和Kafka,下游模块继续订阅Kafka的所有数据,并按照预先配置的存储策略,将其记录到时序数据库(TSDB)或其它目标存储系统中。用户可通过EnOS API查询存储的数据。
主要功能¶
EnOS流数据处理服务具有如下功能:
连续的流数据处理
流数据处理引擎需要处理的数据是实时和连续的。数据流按时间顺序由流数据处理服务订阅和消费。数据是连续生成的,所以数据流被连续地集成到流数据处理系统中。因此,流数据始终是实时的和连续的。
连续高效的计算
EnOS流数据处理服务的计算模式是“事件触发”式的。触发器是前面提到的连续流数据。每当新的流数据发送到流数据处理系统,系统立即启动并执行计算任务。因此,流数据处理是一个连续的过程,并且很高效。
实时流数据集成
流数据触发流数据处理之后,计算结果按照预配的存储策略,被连续记录到目标数据存储器中。
能源领域算法模板
EnOS流数据处理服务沉淀了多套能源领域算法模板,你可按需安装算法模板,并快速配置流数据处理任务。包括
时间窗口聚合模板
电量计算模板(按表读数)
电量计算模板(按瞬时功率)
电量计算模板(按平均功率)
StreamSets算子库
EnOS流数据处理服务提供多套底层封装好的StreamSets原生算子库,供开发者按需安装后,基于业务需求开发定制化的流数据处理任务。更多信息,参考 StreamSets算子参考说明。
资源准备¶
流数据处理资源
配置流数据处理任务前,需确保组织已经通过 EnOS管理门户 > 资源管理 页面申请 流数据处理 资源。有关申请 流数据处理 资源的详细信息,参见 流数据处理资源规格说明。
当业务不再需要运行流数据处理任务,可通过 资源管理 页面删除和释放已申请的流数据处理资源,降低资源使用成本。