使用StreamSets算子进行开发¶
EnOS流数据处理服务提供一整套底层封装好的StreamSets算子,供开发者基于业务需求开发定制化的流数据处理任务。
StreamSets简介¶
StreamSets提供拖拽式的可视化流数据任务设计界面,开发者不需要写代码,通过编排算子组合成流数据处理任务,实现数据采集、数据过滤,数据处理、和数据存储等任务。
流数据处理任务(Pipeline)一般由多个阶段(Stage)和连线连接而成,组成有序的通路,数据会通过这个通路按顺序进行有序的流转。每一个阶段代表了对数据进行的一次读写或者操作。这样的流程构成了一条流数据处理任务。一条流数据处理任务一般包含以下几种类型的Stage:
数据源(Origin)
用于指定数据来源的Stage,数据可从不同的数据源抽取,并将数据输出传递给后面的阶段,例如Kafka Consumer。
处理器(Processor)
用于进行数据转化的Stage,对输入的数据进行规范化或者流转处理(过滤、分流、计算等)。
目标源(Destination)
用于数据存储的Stage,将数据处理完后存入目标系统或者转入另一个Pipeline进行再次处理。
设计StreamSets流数据处理任务¶
EnOS提供设计StreamSets流数据处理任务的模板,通过导入配置模板,可以快速设计一条StreamSets流数据处理任务(Pipeline):
点击
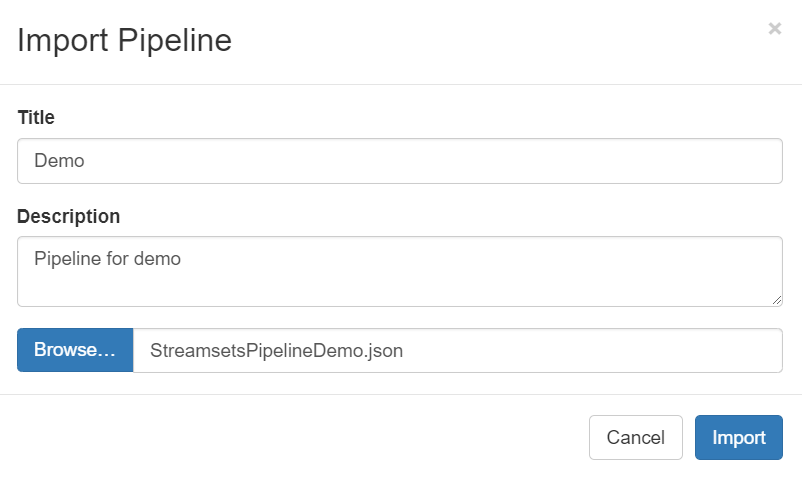
下载StreamSets流数据处理任务配置模板,将模板配置文件streamsets_pipeline_demo.json保存到本地。登录EnOS管理门户,选择 流数据处理 > StreamSets,点击 Create New Pipeline 旁的下三角,选择 Import Pipeline。
在 Import Pipeline 窗口中,输入Pipeline的名称和描述,点击 Browse …,选择保存的模板配置文件,点击 Import。
为Pipeline设置yarn队列:点击页面空白处,然后在 Cluster 配置项下,将 Extra Spark Configuration 参数的
spark.yarn.queue字段的值设置为root.streaming_{orgId},其中orgId为EnOS组织ID(可在EnOS管理门户,身份与授权 > 组织信息 页面获取)。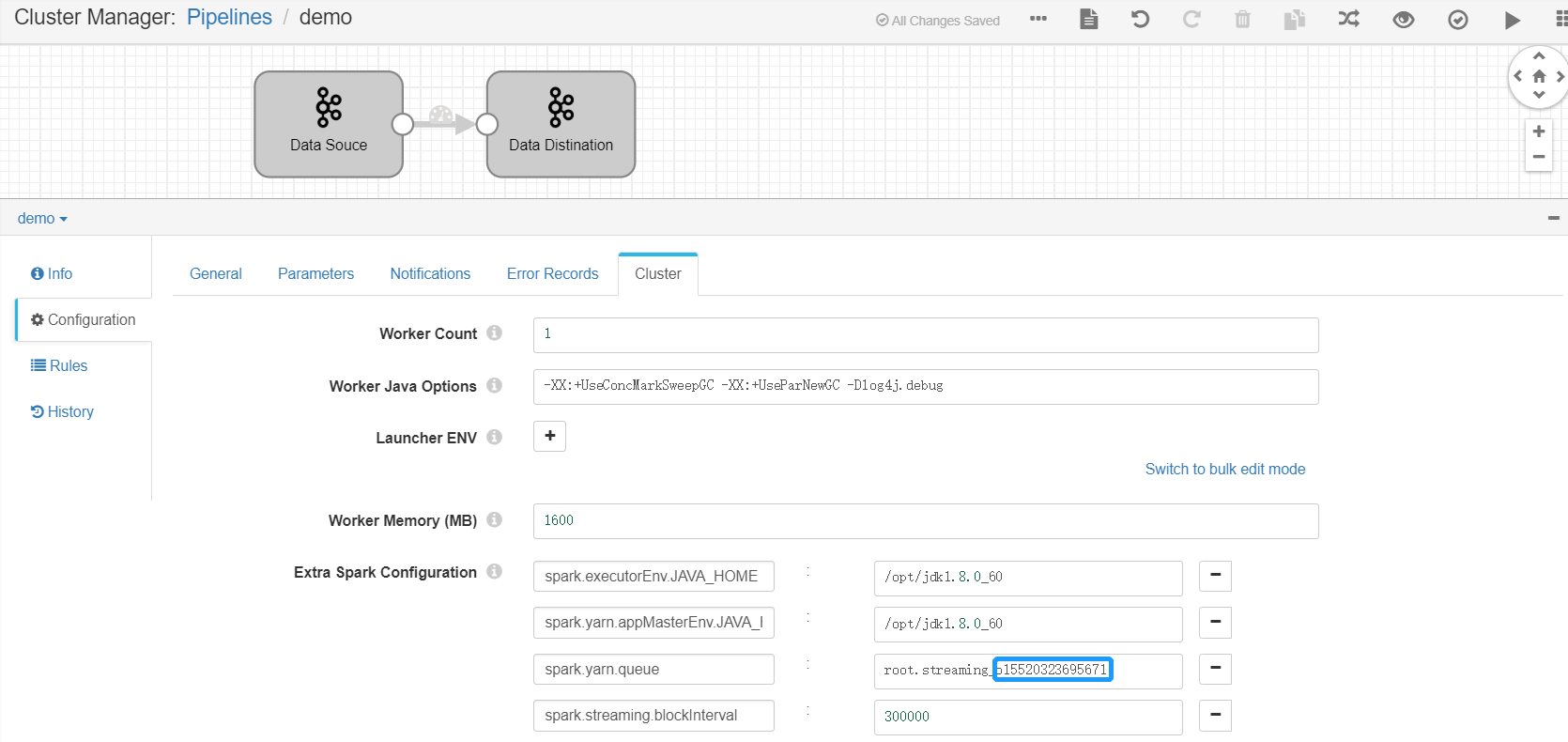
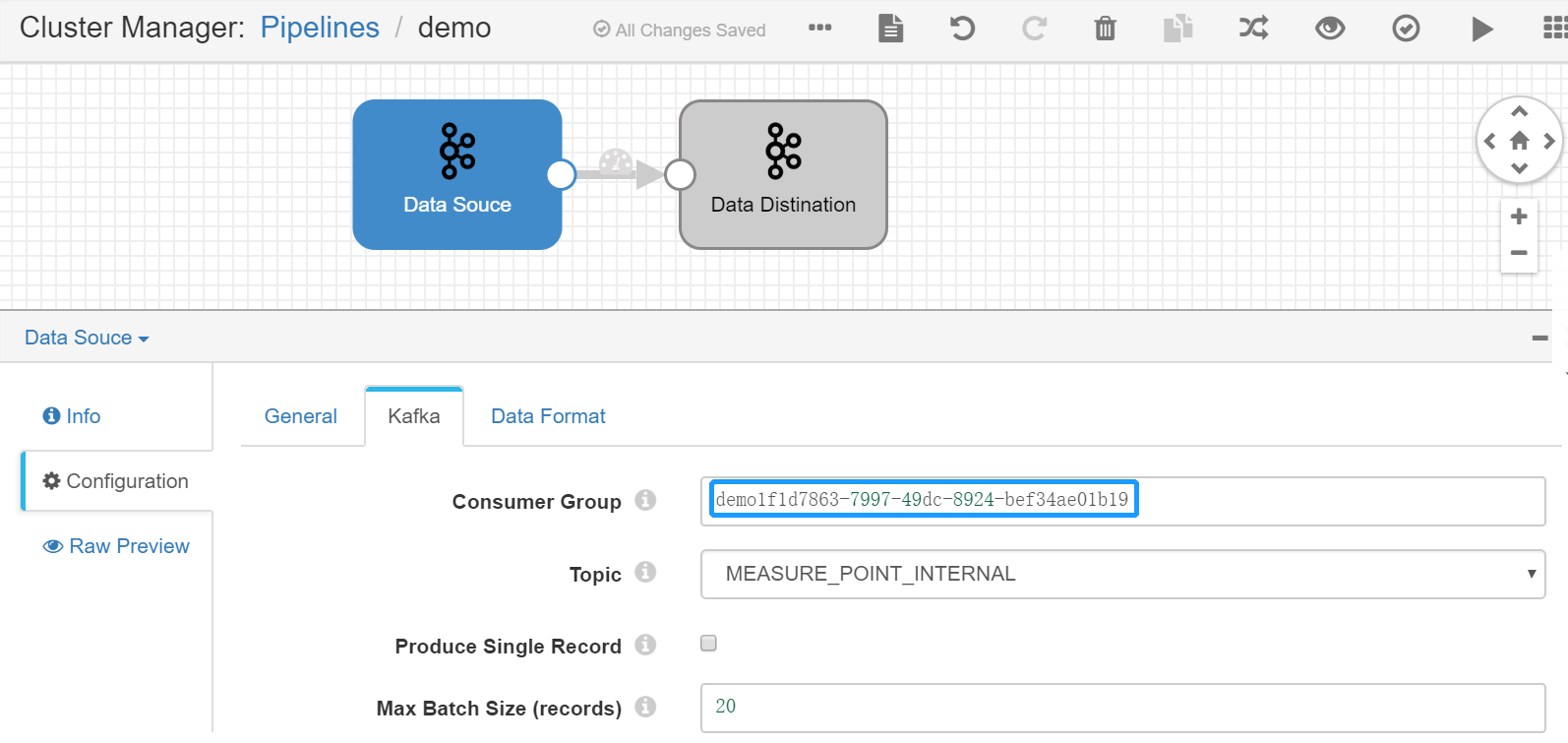
设置Kafka Consumer Group:选中 Data Source Stage,点击 Kafka 配置项,设置 Consumer Group 参数的值(不可与其他Pipeline的consumer group重名,建议以Pipeline ID作为consumer group)。
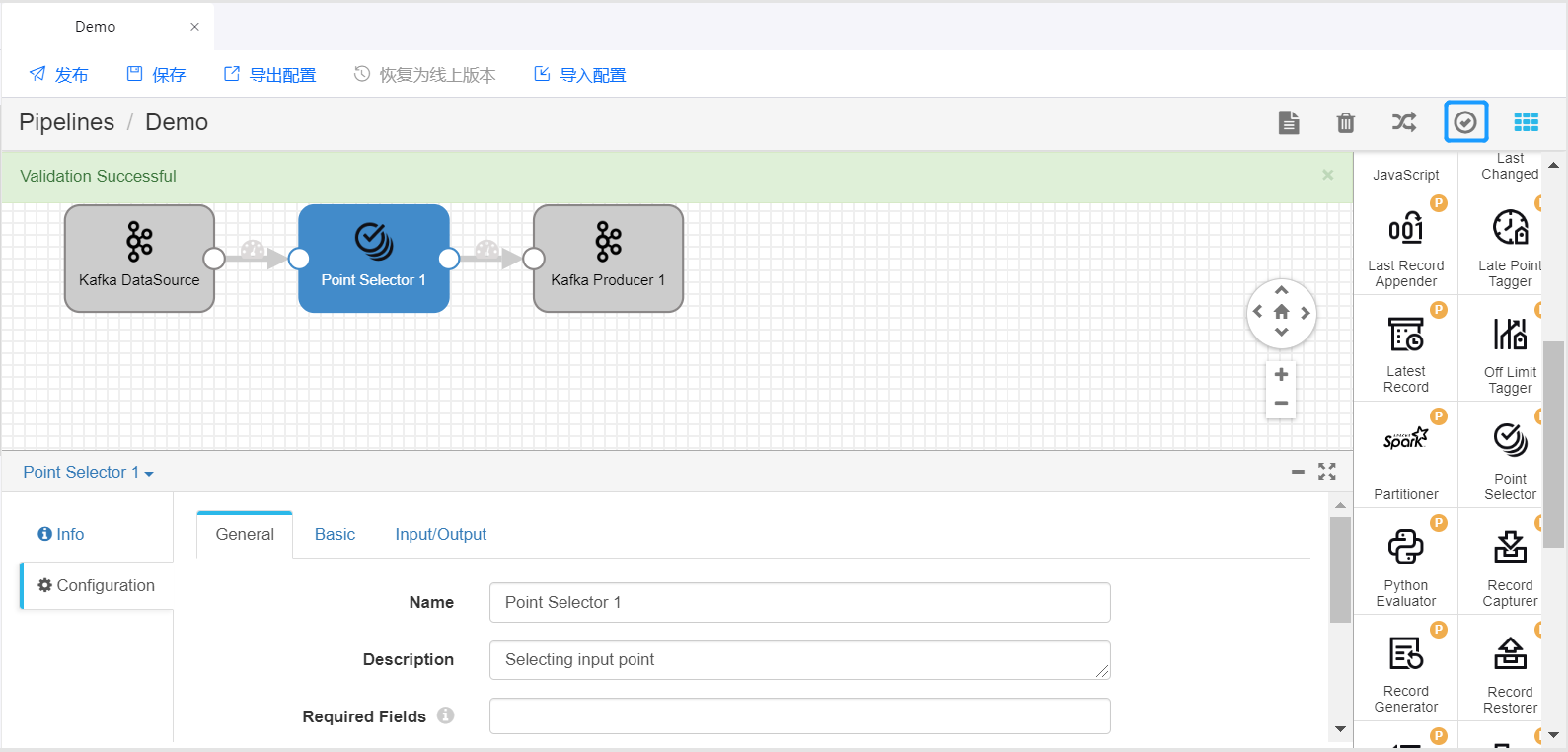
点击页面右上角的 Stage Library,从下拉菜单中,选择需要使用的算子库。点击需要使用的数据处理算子(如Point Selector),将其添加到Pipeline编辑页面。

拖拽Stage和连接线,将添加的Stage编排进Pipeline中。选中添加的算子,在配置项中完成对该算子的参数配置。

重复步骤6、7,将其他算子编排进Pipeline中,并完成各个Stage的参数配置。
点击工具栏中的 Validate 图标,检查Pipeline和算子参数配置是否正确,并按照检查结果修改配置。
更多配置StreamSets Pipeline的详细介绍,参考 StreamSets User Guide。
预览和运行StreamSets流数据处理任务¶
配置检查通过后,即可开始预览和运行Pipeline。
点击工具栏中的 Preview 图标,输入预览配置信息,点击 Run Preview。
点击流数据处理任务中的Stage,查看各个Stage的输入数据和输出数据是否正常。
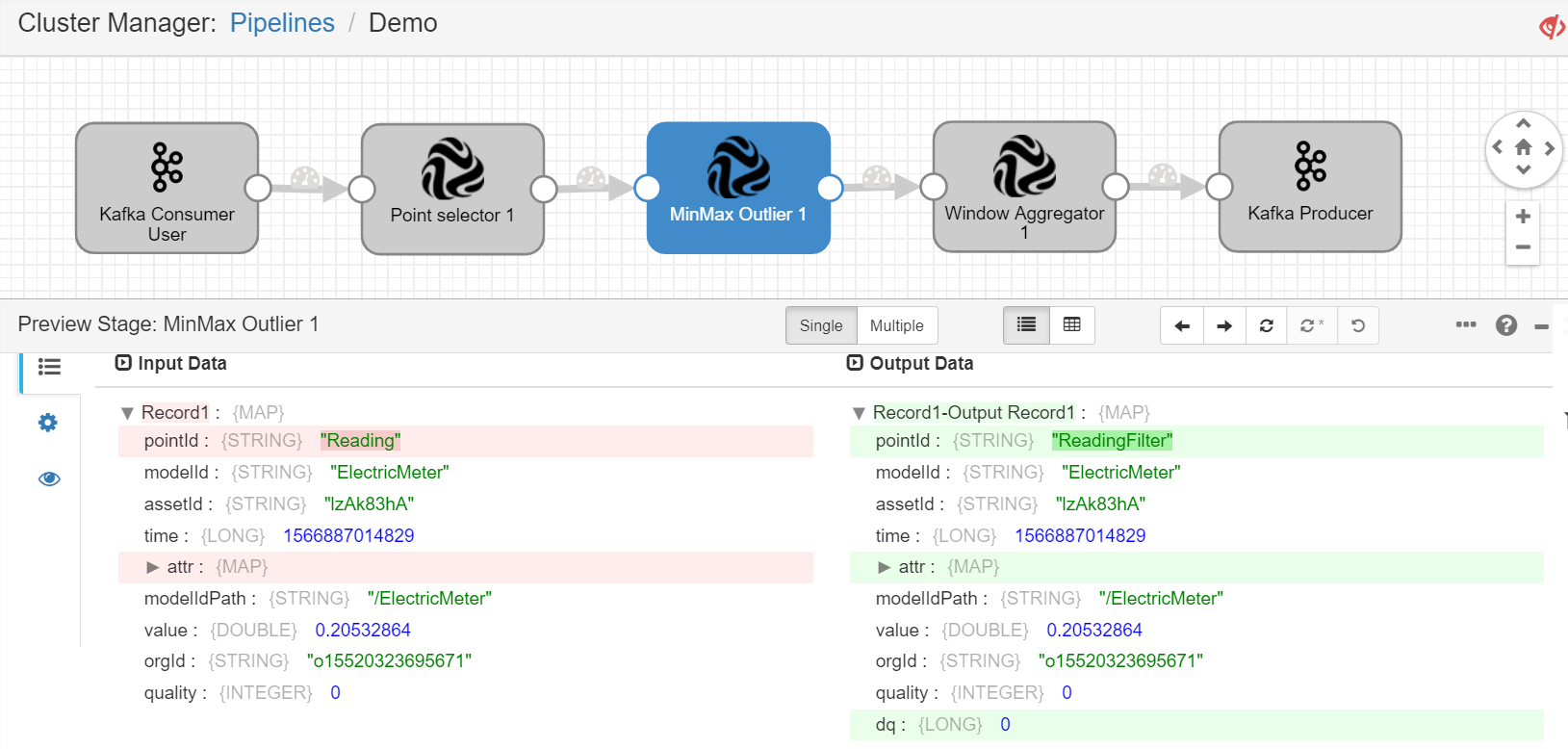
如预览结果正常,停止预览后,点击工具栏中的 Start 图标,开始运行流数据处理任务。
流数据处理任务开始运行之后,在 Monitoring 一栏中,查看各个Stage的数据处理结果。
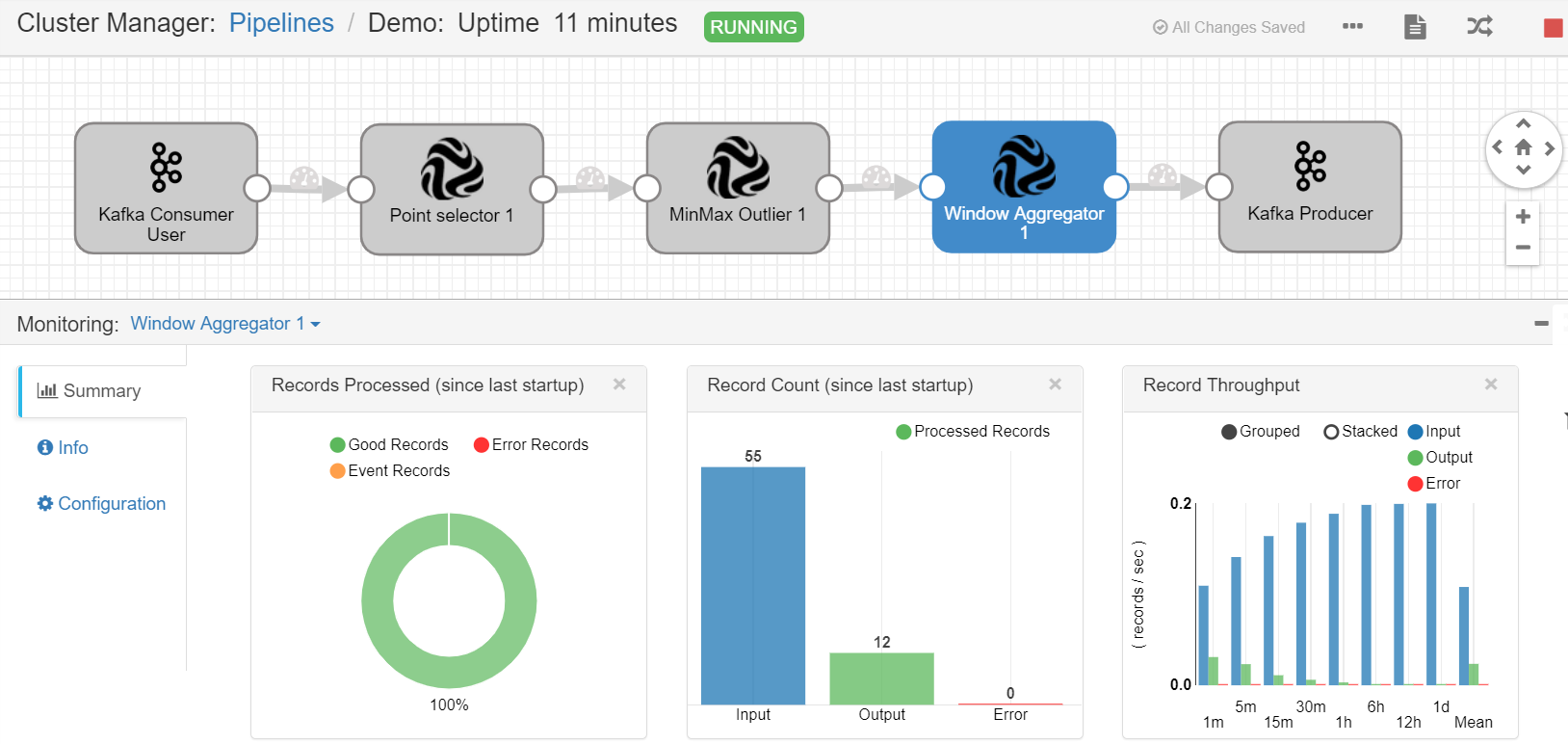
StreamSets算子参考文档¶
对算子的功能、配置参数、和输出结果的详细介绍,参考 StreamSets算子参考说明。
教程¶
学习为更复杂的业务场景开发流数据处理任务,参考 教程:使用StreamSets算子进行开发。