资源准备¶
容器计算资源¶
在使用批数据处理服务的各产品功能之前,需要通过 资源管理 页面申请 批数据处理 - 容器计算 资源。容器计算资源有以下2种模式:
设计态模式:用于批数据处理服务的脚本开发功能,进行脚本执行和调试时需要的容器资源。
运行态模式:用于数据同步或批数据处理功能,运行手动或周期调度任务进行大数据分析时需要的容器资源。
申请容器计算资源¶
可通过以下步骤申请容器计算资源:
使用组织的OU管理员账号登录 EnOS 管理控制台,在左侧导航栏中选择 资源管理。
在 企业数据平台 标签下的 批数据处理-容器计算 一栏中,点击 申请。
选择需要申请的容器计算资源模式和资源规格(支持申请 1~100CU 的计算资源),点击 立即申请。
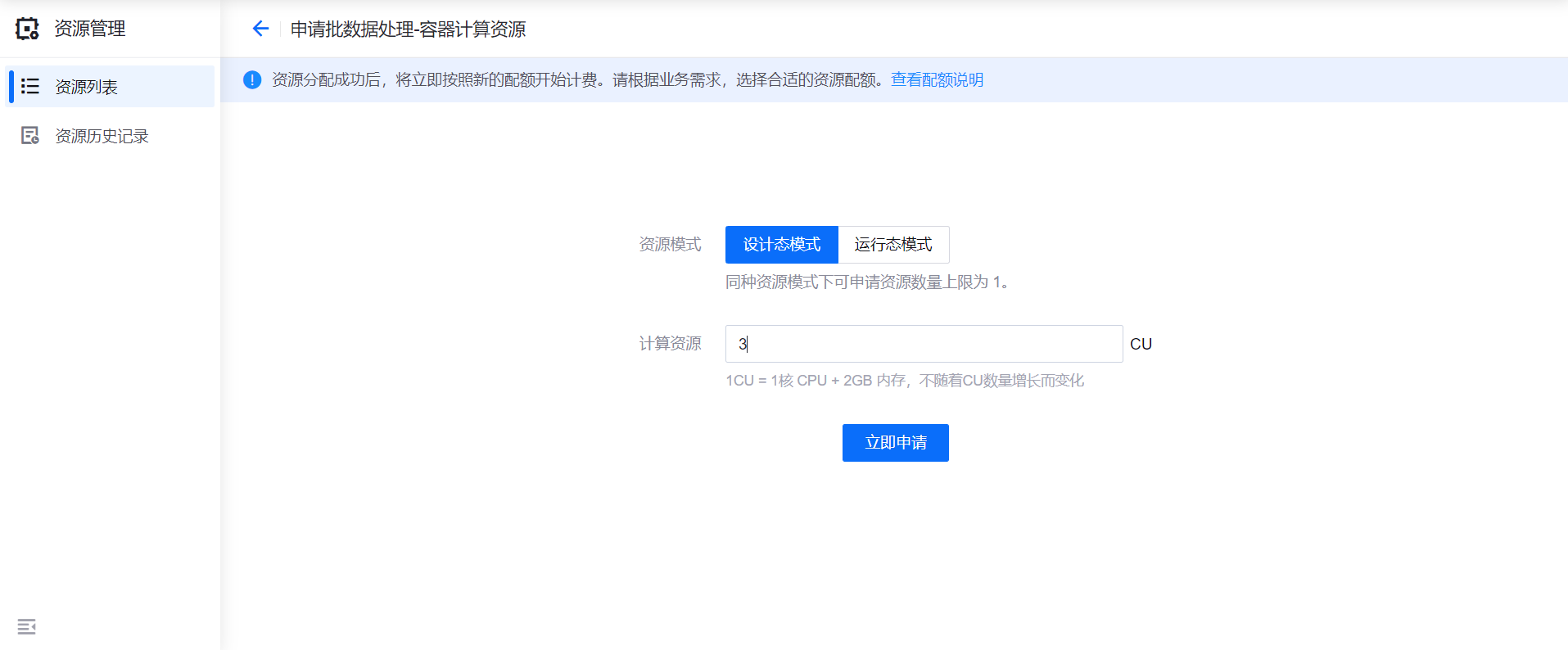
完成容器计算资源申请并审批通过后,资源状态转为 已分配,设计态模式资源的运行状态转为 运行中,即可开始使用资源运行批数据处理任务。
删除容器计算资源
如果业务不再需要运行批数据处理任务,可在停止所有数据分析任务后,在 资源管理 页面删除已申请的批数据处理-容器计算资源,节约资源占用成本。

备注
删除设计态模式容器计算资源之前,需点击 停止 按钮,停止运行资源。
大数据队列资源¶
在以下场景中使用批数据处理服务时,需要通过 资源管理 页面申请 批数据处理 - 大数据队列 资源。
在批数据处理任务流中使用 Python 或 Shell 任务节点,且使用到 HiveSQL 或需要提交 Hadoop yarn 任务时。
批数据处理任务流里使用到数据同步任务节点,同步的数据为结构化数据,且数据同步任务节点里配置的数据源或目标为 HIVE 时。
大数据队列资源有以下2种模式:
计算密集型:若运行任务时 CPU 占用率更高,可选择计算密集型资源。
内存密集型:若运行任务时内存占用率更高,可选择内存密集型资源。
有关使用大数据队列资源的场景说明,参见 大数据队列资源使用说明。
申请或删除大数据队列资源¶
申请或删除大数据队列资源的步骤与容器计算资源相似,可参考以上步骤。