支持的解释器¶
%hive¶
在默认配置下,Hive解释器会使用default队列资源进行数据查询和处理,任务运行不可控且资源无法管理。若需运行资源占用较高的数据查询和处理任务,需申请批数据处理-大数据队列资源,并在notebook中配置申请的队列资源名称。详细步骤如下:
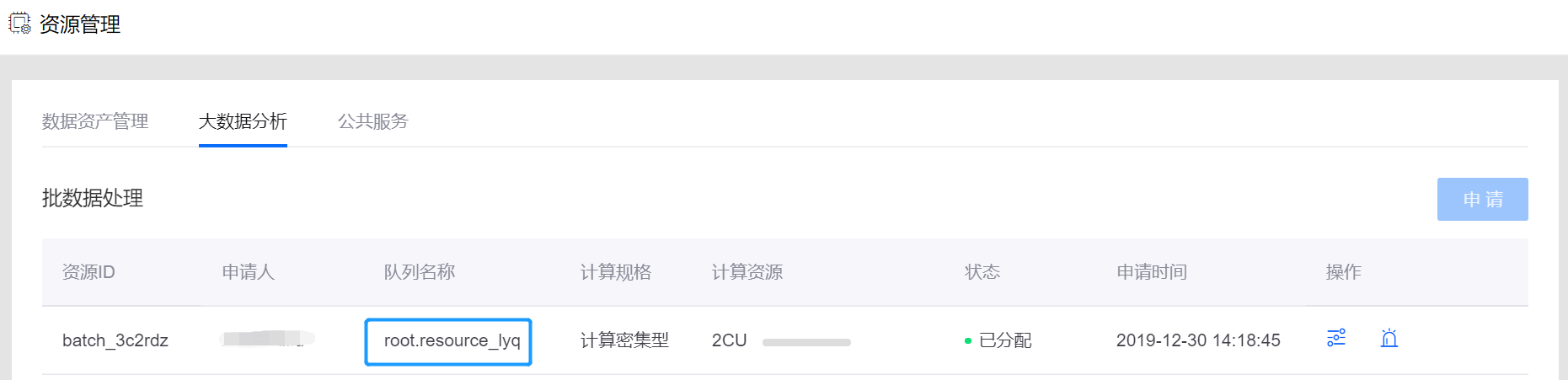
通过 EnOS管理门户 > 资源管理 > 企业数据平台(或使用Zeppelin页面链接),申请 批数据处理-大数据队列 资源。
申请的资源分配成功后,在资源列表的 队列名称 列中,查看大数据队列名称。
打开Zeppelin notebook,切换到%hive解释器,输入并执行以下代码:
set mapreduce.job.queue.name={队列名称}
查看执行结果。

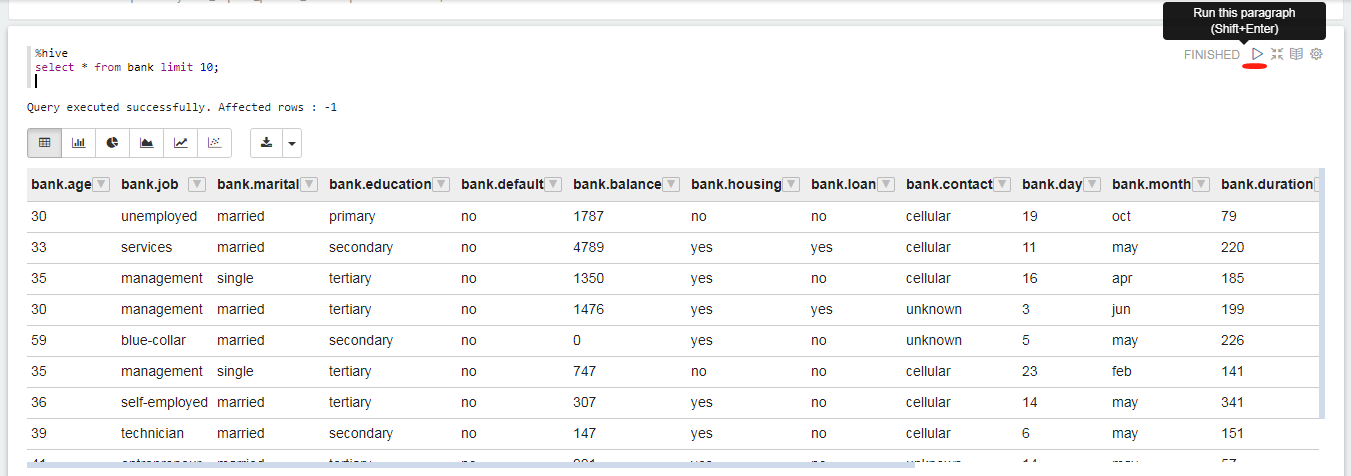
以下代码块提供的示例介绍了如何使用SQL查询原始数据表。
%hive
select * from bank limit 10;
单击  运行代码段落,你将得到类似于以下所示的结果。
运行代码段落,你将得到类似于以下所示的结果。
%livy.spark¶
在默认配置下,Spark解释器会使用default队列资源进行数据查询和处理,任务运行不可控且资源无法管理。若需运行资源占用较高的数据查询和处理任务,需申请批数据处理-大数据队列资源,并在notebook中配置申请的队列资源名称。详细步骤如下:
通过 EnOS管理门户 > 资源管理 > 企业数据平台(或使用Zeppelin页面链接),申请 批数据处理-大数据队列 资源。
申请的资源分配成功后,在资源列表的 队列名称 列中,查看大数据队列名称。
打开Zeppelin notebook,点击页面右上角用户名,选择 Interpreter。
在livy解释器的设置栏中,点击 Edit。

在
livy.spark.yarn.queue字段中,将root.default替换为申请的资源队列名称。
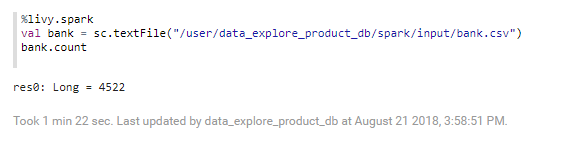
以下代码块提供的示例介绍了如何读取文件bank.csv并计算行数。
%livy.spark
val bank = sc.textFile("/user/data_explore_product_db/spark/input/bank.csv")
bank.count
单击 运行代码段落,你将得到类似于以下所示的结果。
%livy.pyspark¶
在默认配置下,Spark解释器会使用default队列资源进行数据查询和处理,任务运行不可控且资源无法管理。若需运行资源占用较高的数据查询和处理任务,需申请批数据处理队列资源,并在notebook中配置申请的队列资源名称。详见 %livy.spark 中的说明。
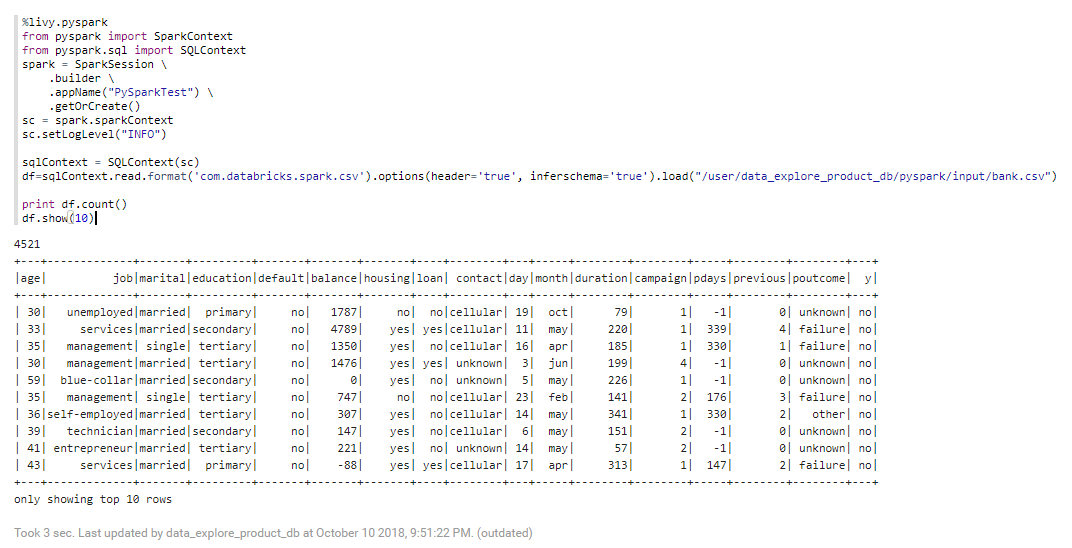
以下代码块提供的示例介绍了读取表文件bank.csv,以及计算除第一行之外的行数并显示前十行数据。
%livy.pyspark
from pyspark import SparkContext
from pyspark.sql import SQLContext
spark = SparkSession \
.builder \
.appName("PySparkTest") \
.getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("INFO")
sqlContext = SQLContext(sc)
df=sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load("/user/data_explore_product_db/pyspark/input/bank.csv")
print df.count()
df.show(10)
单击 运行代码段落,你将得到类似于以下所示的结果。
%md¶
以下代码块提供了markdown的示例:
%md
# hello world
- **hello world**
单击 运行代码段落,你将得到类似于以下所示的结果。

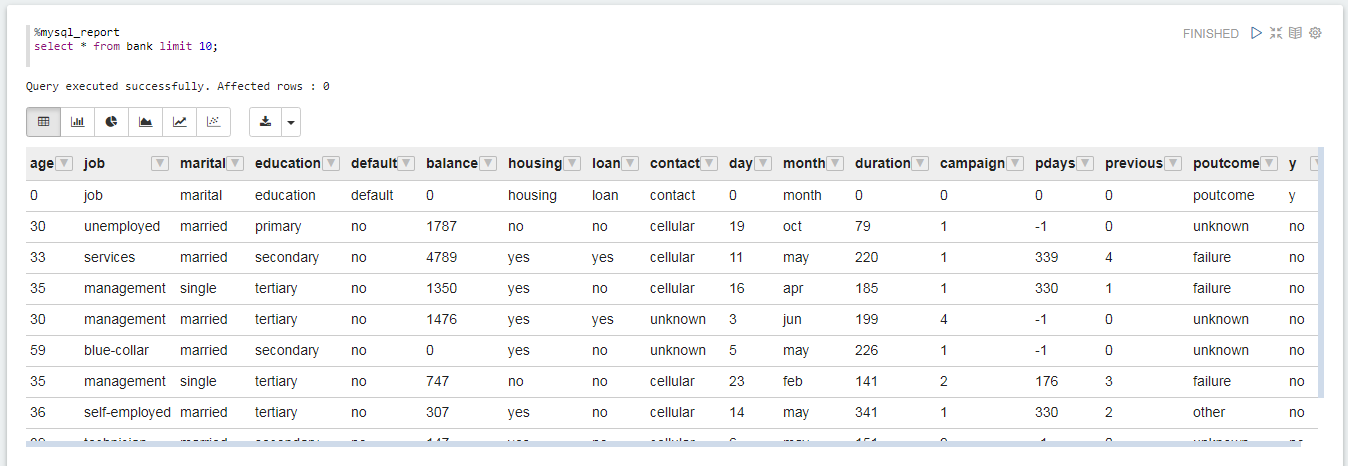
%mysql_report¶
以下代码块提供的示例介绍了如何从EnOS数据报表数据库中检索数据:
%mysql_report
select * from bank limit 10;
单击 运行代码段落,你将得到类似于以下所示的结果。
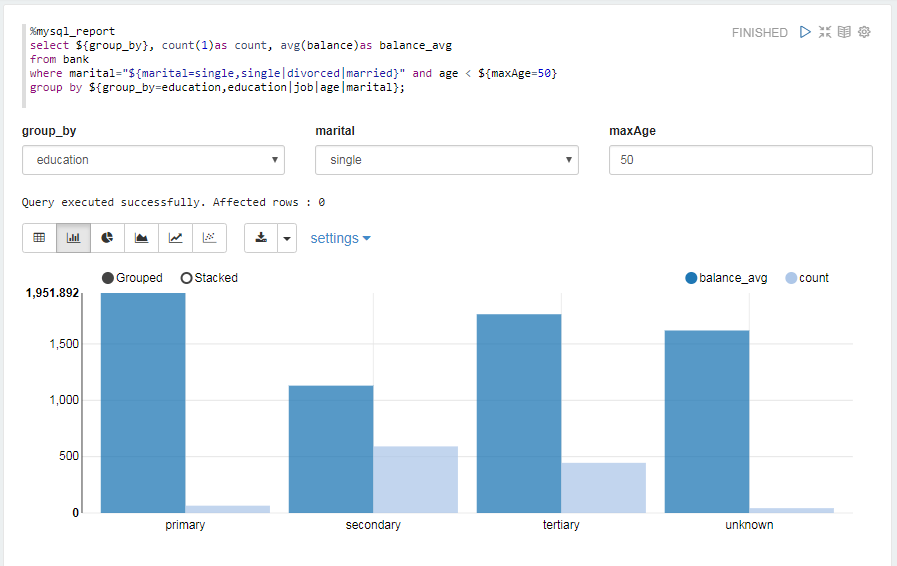
以下代码块提供的示例介绍了如何使用复杂的SQL语句查询检索数据:
%mysql_report
select ${group_by}, count(1)as count, avg(balance)as balance_avg
from bank
where marital="${marital=single,single|divorced|married}" and age < ${maxAge=50}
group by ${group_by=education,education|job|age|marital};
单击 运行代码段落,你将得到类似于以下所示的结果。
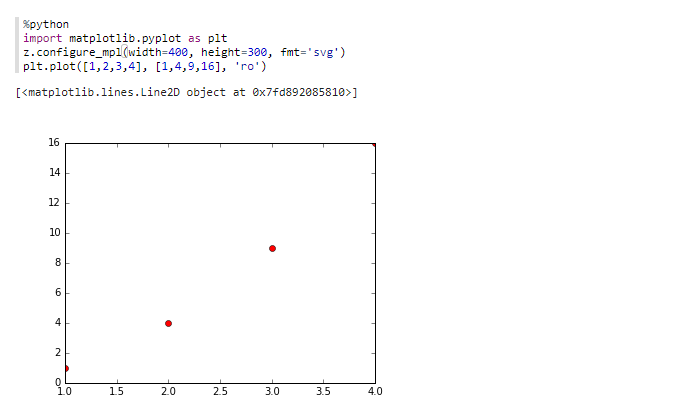
%python¶
以下代码块提供的示例介绍了python的基本操作,即如何使用python标记两个坐标点。
%python
import matplotlib.pyplot as plt
z.configure_mpl(width=400, height=300, fmt='svg')
plt.plot([1,2,3,4], [1,4,9,16], 'ro')
单击 运行代码段落,你将得到类似于以下所示的结果。
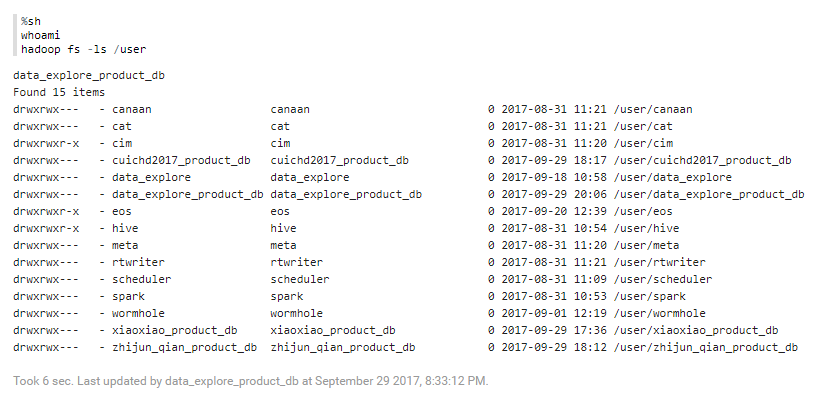
%sh¶
以下代码块提供的示例介绍了shell的基本操作。
%sh
whoami
hadoop fs -ls /user
单击 运行代码段落,你将得到类似于以下所示的结果。