单元 4:计算电量损失¶
在本单元中,你将依据以下逻辑计算海上风机的电量损失。
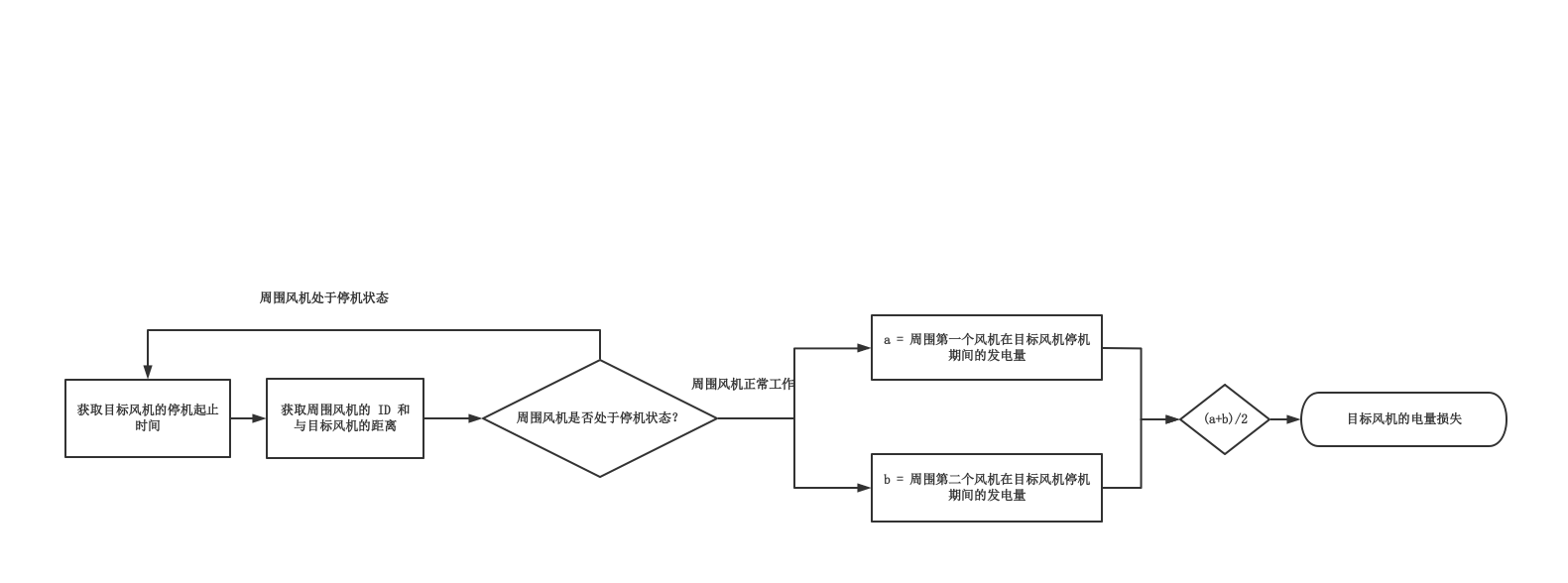
本单元介绍如何通过以下方式在智能工作室中计算海上风机电量损失:
在 智能实验室 中利用在 单元 3:准备代码 中创建的 Notebook 实例和上传的样例代码文件计算电量损失。
在 智能任务流 中导入样例任务流计算电量损失。
在 智能任务流 中新建低代码任务流计算电量损失。
方法 1:在 Notebook 实例中计算电量损失¶
你可以在 Notebook 实例中通过以下步骤使用上传的样例代码文件计算海上风力发电机组的电量损失并将计算结果上传到 Hive 数据源中。
步骤 1:运行样例代码
在 单元 3:准备代码 中,你已经上传了样例代码文件:power-loss.ipynb。通过以下步骤运行此样例代码文件计算海上风力发电机组的电量损失:
登录 EnOS 管理控制台并在左侧导航栏中选择 智能工作室 > 智能实验室。
在实例列表中选择 power-loss 打开此实例。
在 power-loss 文件夹中选择 power-loss.ipynb 打开此文件。可参照文件中给出的注释熟悉整体运算逻辑。
在文件窗口上方工具栏中选择双箭头图标
 ,重启此 kernel 并重新运行 Notebook 文件。
,重启此 kernel 并重新运行 Notebook 文件。
Notebook 文件运行结束后,将在此目录中创建名为 power-loss.csv 的结果文件。
步骤 2:上传计算结果到 Hive 数据源¶
在 power-loss 实例页面中,打开在 单元 3:准备代码 中创建的终端窗口。
在终端窗口中输入以下命令并运行,将结果文件上传至内部文档中。
hdfs dfs -put -f power-loss.csv /user/data_{ouid}/{directory}
其中:
{ouid} 指当前 OU 的 ID。如需获取当前 OU 的 ID,将光标悬浮到顶部状态栏中的 OU 名称上。
{directory} 指 HDFS 中文件的存储目录。若指定的文件夹不存在,系统将自动创建同名文件夹用于存储结果文件。
方法 2:基于样例任务流计算电量损失¶
如需快速了解如何在智能任务流中利用算子处理数据,你可以通过导入内置的样例任务流并基于此样例任务流计算海上风机的电量损失。
步骤 1:导出样例任务流¶
为了基于样例任务流构建自定义任务流,首先需要通过以下步骤导出样例任务流:
登录 EnOS 管理控制台并从左侧导航栏中选择 智能工作室 > 智能任务流。
选择 样例作业流 标签页,并选择 power-loss-calculation 样例任务流的 任务流查看 按钮。
选择 导出 导出样例任务流配置。
步骤 2:导入样例任务流¶
通过以下步骤导入样例任务流配置文件,从而复用样例任务流的任务流结构、算子以及全局参数等信息:
在左侧导航栏中选择 智能工作室 > 智能任务流。
在自建任务流标签页中选择的 新建实验。
在弹窗中输入
power-loss作为此实验的名称。选择 确定 创建实验并打开此实验的任务流画布,进行任务流的设计和开发。
选择 导入 按钮
 ,导入样例任务流配置文件。
,导入样例任务流配置文件。
步骤 3:配置全局参数¶
为了让任务流设计过程更为简单高效,你可以将全局适用的参数设置为全局参数,避免重复配置。本教程中使用的全局参数已包含于样例任务流中。选择画布右侧的 任务流设置 图标配置全局参数。其中各个参数的含义如下所示。
名称 |
类型 |
参数值 |
描述 |
|---|---|---|---|
wtg_10m_dts |
string |
sample-10min-run-demo |
指定包含 10 分钟内平均生成电量数据的样例数据集。 |
dwntm_recds_dts |
string |
sample-downtime-records-demo |
指定包含风机停机时间信息的样例数据集。 |
sur_wtg_dts |
string |
sample-surround-info-demo |
指定包含风机与周围风机距离数据的样例数据集。 |
hadoop_resource |
boolean |
true 或 false |
指定是否将计算结果存储于 Hive 和 HDFS 中。 |
hive_source |
hive_source |
从下拉列表中选择本 OU 申请的数据仓库存储资源。 |
指定用于存储计算结果的 Hive 源。 |
hdfs_source |
hdfs_source |
从下拉列表中选择本 OU 申请的文件存储 HDFS 资源。 |
指定用于存储计算结果的 HDFS 源。 |
ouid |
string |
输入本 OU 的 ID。可将光标悬停在顶部导航栏中的 OU 名称上获取 OU ID。 |
指定 OU 的 ID。 |
步骤 4:检查任务流中的算子¶
你可以在样例任务流中查看到以下算子。
名称 |
描述 |
|---|---|
Calculate Power Loss |
此 PythonEx 算子用于基于指定的样例数据集计算海上风机电量损失,并生成名为 power-loss 的计算结果文件。 |
Export to Hive? |
此 Condition 算子用于在表达式满足 Reference | hive_source | != | Reference | <null> 时将计算结果存储到 Hive 数据源。[1] |
Upload to HDFS? |
此 Condition 算子位于 Export to Hive? 子画布中,用于在表达式满足 Reference | hive_source | != | Reference | <null> 时将计算结果存储到 HDFS 数据源。[1] |
PythonCode |
此 PythonCode 算子位于 Export to HDFS? 子画布中,用于创建存放计算结果的 csv 数据表。 |
Upload csv to HDFS |
此 HDFS Uploader 算子位于 Export to HDFS? 子画布中,用于将 csv 文件存储到指定的 HDFS 数据源中。 |
Create Hive Table |
此 Hive 算子位于 Export to HDFS? 子画布中,用于创建存放计算结果的 Hive 数据表。 |
[1] 此处的 <null> 指此参数值为空。
步骤 5:运行任务流¶
在 power-loss 任务流画布中的顶部工具栏中选择 运行
 。
。在弹窗中选择 确认 运行任务流。
方法 3:新建任务流计算电量损失¶
你也可以从头开始利用算子设计一个低代码任务流,计算海上风机电量损失并将计算结果上传到 Hive 中。有关相关算子的更多信息,参见 算子参考文档。
步骤 1:新建实验¶
在左侧导航栏中选择 智能工作室 > 智能任务流。
在自建作业流标签页中选择 新建实验。
在弹窗中输入
power-loss作为此任务流的名称。选择 确定 创建实验并打开此实验的画布页面,设计任务流。
步骤 2:添加全局参数¶
为了让任务流设计过程更为简单高效,通过以下步骤将全局适用的参数设置为全局参数从而避免重复配置:
在 power-loss 任务流画布中选择 任务流设置
 打开任务流设置面板。
打开任务流设置面板。在任务流设置面板的配置参数部分选择 添加参数 并添加以下全局参数。
名称 |
类型 |
参数值 |
描述 |
|---|---|---|---|
wtg_10m_dts |
string |
sample-10min-run-demo |
指定包含 10 分钟内平均生成电量数据的样例数据集。 |
dwntm_recds_dts |
string |
sample-downtime-records-demo |
指定包含风机停机时间信息的样例数据集。 |
sur_wtg_dts |
string |
sample-surround-info-demo |
指定包含风机与周围风机距离数据的样例数据集。 |
hadoop_resource |
boolean |
true 或 false |
指定是否将计算结果存储于 Hive 和 HDFS 中。 |
hive_source |
hive_source |
从下拉列表中选择本 OU 申请的数据仓库存储资源。 |
指定用于存储计算结果的 Hive 源。 |
hdfs_source |
hdfs_source |
从下拉列表中选择本 OU 申请的文件存储 HDFS 资源。 |
指定用于存储计算结果的 HDFS 源。 |
ouid |
string |
输入本 OU 的 ID。可将光标悬停在顶部导航栏中的 OU 名称上获取 OU ID。 |
指定 OU 的 ID。 |
步骤 3:配置算子¶
你需要在任务流画布中添加以下算子计算海上风机的电量损失。
算子 |
描述 |
|---|---|
PythonEx |
计算电量损失。 |
Condition 1 |
判断是否将结果存储到 Hive。 |
Condition 2 |
判断是否将结果存储到 HDFS。 |
PythonCode |
上传结果至 Hive。 |
Hive |
创建 Hive 数据表存储数据。 |
HDFS Uploader |
以 CSV 文件格式将结果上传至 HDFS。 |
配置计算电量损失的 PythonEx 算子¶
在 power-loss 任务流画布页面,从左侧算子列表中拖拽一个 PythonEx 算子到画布中。
选择此 Hive 算子并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
workspace
声明
选择 在 单元 3:准备代码 中创建的 Notebook 实例文件夹。
entrypoint
声明
选择 power-loss.py。
requirements
声明
选择 requirement.txt。
在 输入参数 部分选择 添加参数 并重复 3 次,添加 3 个输入参数并配置以下信息。
名称
类型
引用/声明
参数值
描述
sur_wtg_dts
string
引用
sur_wtg_dts
获取样例数据集中的周围风机距离数据。
dwntm_recds_dts
string
引用
dwntm_recds_dts
获取样例数据集中的风机停机数据。
wtg_10m_dts
string
引用
wtg_10m_dts
获取样例数据集中的风机发电量数据。
在 输出参数 部分选择 添加参数,添加一个名为
result_file且类型为 file 的输出参数。
配置将结果保存到 Hive 的 Condition 算子¶
在 power-loss 任务流画布页面,从左侧算子列表中拖拽一个 Condition 算子到画布中。
连接 PythonEx 算子的输出锚点与此 Condition 算子的输入锚点。
选择此算子,并配置以下信息作为此 Condition 算子的表达式。
Reference | hive_source | != | Declaration | <null>
上述配置完成后,双击此算子打开子画布。你需要在子画布中添加另一个 Condition 算子,将结果上传到 HDFS。
配置保存结果到 HDFS 的 Condition 算子¶
在上述步骤中创建的 Condition 算子的子画布页面中,从左侧算子列表中拖拽一个 Condition 算子到画布中。
选择此算子,并配置以下信息作为此 Condition 算子的表达式。
Reference | hive_source | != | Declaration | <null>
上述配置完成后,双击此算子打开子画布。你需要在子画布中添加以下算子:
上传结果到 Hive 的 PythonCode 算子
创建 Hive 数据表的 Hive 算子
上传结果到 HDFS 的 HDFS Uploader 算子
配置上传结果至 Hive 的 PythonCode 算子¶
在上述步骤中创建的第二个 Condition 算子的子画布页面中,从左侧算子列表中拖拽一个 PythonCode 算子到画布中。
选择此 Hive 算子并在右侧面板的 code 参数中输入以下代码。
import json import argparse from pathlib import Path # Define an ArgumentParser parser = argparse.ArgumentParser() parser.add_argument("--ouid", type=str, required=True) parser.add_argument("--sql_statements", type=str, required=True) parser.add_argument("--hdfs_dest", type=str, required=True) args = parser.parse_args() target_sqls = [f"""create external table if not exists `power_loss`( `site_id` string comment '场站', `device_id` string comment '风机', `iec_group_id` string comment '状态码', `iec_level4_description` string comment '状态描述', `start_time` timestamp comment '启始时间', `end_time` timestamp comment '结束时间', `sur_avb_wtg1` string comment '周围可用风机1', `sur_avb_wtg2` string comment '周围可用风机2', `power-loss1` string comment '电量损失1(kWh)', `power-loss2` string comment '电量损失2(kWh)', `power-loss-avg` string comment '电量损失均值(kWh)' ) COMMENT '电量损失表' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim'=',', 'serialization.format'=',') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/user/data_{args.ouid}/hbjtdemo/power-loss' TBLPROPERTIES ( 'skip.header.line.count'='1', 'timestamp.formats' = 'yyyy-MM-dd HH:mm:ss')"""] Path(args.sql_statements).parent.mkdir(parents=True, exist_ok=True) with open(args.sql_statements, 'w') as f: json.dump(target_sqls, f) Path(args.hdfs_dest).parent.mkdir(parents=True, exist_ok=True) with open(args.hdfs_dest, 'w') as f: f.write(f"/user/data_{args.ouid}/hbjtdemo/power-loss")
在 输入参数 部分选择 添加参数 并配置以下信息。
名称
类型
引用/声明
参数值
描述
ouid
string
引用
ouid
指定当前 OU 的 OU ID。
在 输出参数 部分选择 添加参数 并重复 2 次,添加 2 个输出参数并配置以下信息。
名称
类型
sql_statement
list
hdfs_dest
string
配置用于创建 Hive 数据表的 Hive 算子¶
在上述步骤中创建的第二个 Condition 算子的子画布页面中,从左侧算子列表中拖拽一个 Hive 算子到画布中。
连接 PythonCode 算子的输出锚点到此 Hive 算子的输入锚点。
选择此 Hive 算子并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
data_source_name
引用
选择 hive_source。
sqls
引用
选择 pythonCode.sql_statement。
配置用于上传结果的 HDFS Uploader 算子¶
在上述步骤中创建的第二个 Condition 算子的子画布页面中,从左侧算子列表中拖拽一个 HDFS Uploader 算子到画布中。
连接 PythonCode 算子和 Hive 算子的输出锚点到此 HDFS Uploader 算子的输入锚点。
选择此 Hive 算子并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
data_source_name
引用
选择 hdfs_source。
file
引用
选择 PythonEX.result_file。
dest
声明
选择 PythonCode.hdfs_dest。
在 输入参数 部分选择 添加参数,添加 1 个输入参数并配置以下信息。
名称
类型
引用/声明
参数值
描述
overwrite
boolean
声明
true
若存在同名数据表,用新数据表覆盖旧数据表。
步骤 4:运行任务流¶
在 power-loss 画布中,选择顶部工具栏中的 运行
。在弹窗中选择 确认 运行此任务流。
除了通过上述步骤,选择 运行 外,你也可以配置任务流调度从而让任务流按照调度配置自动运行。更多信息,参见 配置任务流调度。
(可选) 步骤 5:查看任务流运行状态¶
通过以下步骤查看任务流的运行状态:
在 智能任务流 > 自定义作业流 标签页中选择 power-loss 任务流的 运行实例 按钮。
在实例列表中选择相应运行实例名称。
在以下标签页中查看 power-loss 任务流的运行状态:
在 DAG 图 标签页下,可查看任务流实例的运行结果,包括运行流程、输入输出、日志以及算子 Pod 信息。
在 详情 标签页下,可查看任务流运行的基本详情、运行参数和高级配置信息。
在 甘特 标签页下,可查看算子运行的时间分布状况以及算子运行状态。