Unit 4. Calculating Power Loss¶
In this tutorial, you can calculate the power loss of offshore wind turbines according to the following operation logic.
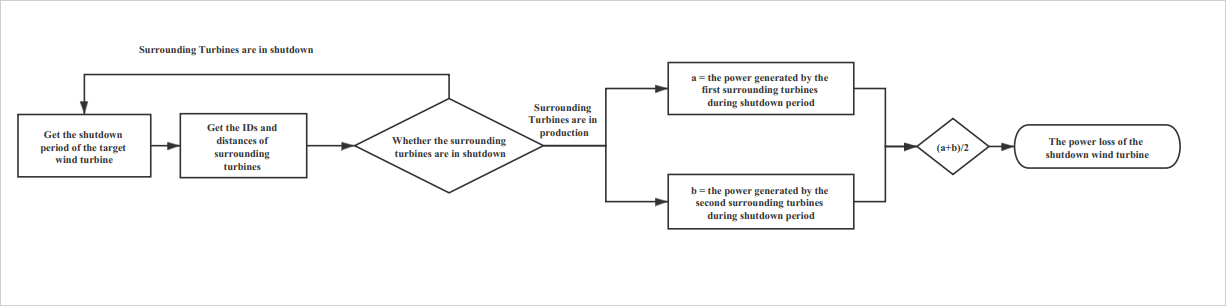
This unit describes how to calculate the power loss of offshore wind turbines by the following ways:
In AI Lab, use the sample codes to calculate power loss in the Notebook instance you created in Unit 3.
In AI Pipelines, import a sample pipeline to calculate power loss.
In AI Pipelines, design a low-code pipeline from scratch to calculate power loss.
Option 1. Calculating in a Notebook Instance¶
You can use sample codes in a Notebook instance to calculate the power loss of offshore wind turbines and upload the calculation results into Hive.
Step 1. Running Codes to Calculate¶
In Unit 3, you have already uploaded the sample code file (power-loss.ipynb) that can be used to calculate power loss. Run the uploaded codes to calculate the power loss of offshore wind turbines by the following steps:
Log in to EnOS Management Console and select AI Studio > AI Lab on the left navigation pane.
Select power-loss on the Notebook Instance tab to open the instance.
Open the power-loss.ipynb in the power-loss folder. You can refer to the comments in the file to get familiar with the operation logic.
Select the double-arrow icon
 on the tool bar to restart kernel and re-run the whole notebook.
on the tool bar to restart kernel and re-run the whole notebook.
You can see the result file named power-loss.csv appear in the directory after successfully ru-run the whole notebook.
Step 2. Uploading Results to Internal Storage¶
In the power-loss instance page, open the terminal you created in Step 1. Running Codes to Calculate.
Enter and run the following code in the terminal for uploading the result file to internal storage.
hdfs dfs -put -f power-loss.csv /user/data_{ouid}/{directory}
Where:
{ouid} refers to the current OU ID. You can get the current OU ID by hovering over the OU name on the top toolbar.
{directory} refers to the target folder in HDFS to store the file. If the folder you designated does not exist, a new folder will be created with the name you entered.
Option 2. Calculating Based on a Sample Pipeline¶
If you want to get a quick start on how to process data with operators in AI Pipelines, you can design a pipeline by importing the built-in sample pipeline to calculate power loss of offshore wind turbines.
Step 1. Exporting Sample Pipeline¶
To design your own pipeline based on a sample pipeline, export the sample pipeline first by the following steps:
Log in to EnOS Management Console and select AI Studio > AI Pipelines on the left navigation pane.
On the Sample Pipeline tab, select power-loss-calculation > Pipeline View.
Select Export to export the sample pipeline configuration in a JSON file.
Step 2. Importing Sample Pipeline¶
To reuse the information of the sample pipeline such as the structure, operators, and global parameters, import the exported JSON files by the following steps:
Select AI Studio > AI Pipelines on the left navigation pane.
Select New Experiment on the Custom Pipeline tab.
Enter
power-lossas the name of the experiment in the popup window.Select OK to create the experiment, and you can see the canvas for designing a pipeline.
Select Import
 to import the exported sample pipeline configuration.
to import the exported sample pipeline configuration.
Step 3. Checking Global Parameters¶
For a more efficient and simpler pipeline design process, you can set globally applicable parameters as global parameters to avoid repetitive configuration. The global parameters used in this tutorial are included in the sample pipeline configuration file, select Workflow setting  to check the global parameters.
to check the global parameters.
Name |
Type |
Value |
Description |
|---|---|---|---|
wtg_10m_dts |
string |
sample-10min-run-demo |
Specify the sample data of generated power in 10 minutes. |
dwntm_recds_dts |
string |
sample-downtime-records-demo |
Specify the sample data of shutdown time periods. |
sur_wtg_dts |
string |
sample-surround-info-demo |
Specify the sample data of the distances between the shutdown turbines and surrounding turbines. |
hadoop_resource |
boolean |
true or false |
Determine whether to export the result file to Hive and HDFS. |
hive_source |
hive_source |
Select the Data Warehouse Storage resource of your OU from the dropdown list. |
Specify the target Hive source where you upload the result file. |
hdfs_source |
hdfs_source |
Select the File Storage HDFS resource of your OU from the dropdown list. |
Specify the target HDFS source where you upload the result file. |
ouid |
string |
Enter your OU ID, which you can get by hovering over the OU name on the top navigation bar. |
Specify your OU ID. |
Step 4. Checking Pipeline Operators¶
In this sample pipeline, you can see the following operators.
Operator Name |
Description |
|---|---|
Calculate Power Loss |
This PythonEx operator is used to calculate the power loss of offshore wind turbines based on the specified sample datasets and generate the result file named power-loss. |
Export to Hive? |
This Condition operator is used to export the result file to the specified Hive source, if the operator expression is Reference | hive_source | != | Reference | <null>. [1] |
Upload to HDFS? |
This Condition operator in the “Export to Hive?” sub-canvas is used to upload the result file to the specified HDFS source, if the operator expression is Reference | hdfs_source | != | Reference | <null>. [1] |
PythonCode |
This PythonCode operator in the “Export to HDFS?” sub-canvas is used to create a csv table containing calculating results. |
Upload csv to HDFS |
This HDFS Uploader operator in the “Export to HDFS?” sub-canvas is used to upload the result csv file to the specified HDFS. |
Create Hive Table |
This Hive operator in the “Export to HDFS?” sub-canvas is used to create a Hive table containing calculating results. |
[1] <null> refers to leaving the value here blank.
Step 5. Running the Pipeline¶
On the power-loss pipeline canvas, select Run
 on the top toolbar.
on the top toolbar.Select OK to run the pipeline in the pop-up window.
Option 3. Calculating by designing a Pipeline from scratch¶
You can also design a low-code pipeline with operators from scratch to calculate the power loss of offshore wind turbines and upload the calculating results into Hive. For more information on the operators you will use, see Operator Reference.
Step 1. Creating an Experiment¶
Select AI Studio > AI Pipelines on the left navigation pane.
Select New Experiment on the Custom Pipeline tab.
Enter
power-lossas the name of the experiment in the popup window.Select OK to create the experiment, and you can see the canvas for designing a pipeline.
Step 2. Adding Global Parameters¶
For a more efficient and easier pipeline design process, you can set the parameters that are globally applied in this pipeline as global parameters to avoid repetitive configuration by the following steps:
On the power-loss pipeline canvas, select Workflow Setting
to open the Workflow Setting panel.Select Add Parameter to add the following global parameters in the Configuration Parameters section.
Name |
Type |
Value |
Description |
|---|---|---|---|
wtg_10m_dts |
string |
sample-10min-run-demo |
Specify the sample data of generated power in 10 minutes. |
dwntm_recds_dts |
string |
sample-downtime-records-demo |
Specify the sample data of shutdown time periods. |
sur_wtg_dts |
string |
sample-surround-info-demo |
Specify the sample data of the distances between the shutdown turbines and surrounding turbines. |
hadoop_resource |
boolean |
true or false |
Determine whether to export the result file to Hive and HDFS. |
hive_source |
hive_source |
Select the Data Warehouse Storage resource of your OU from the dropdown list. |
Specify the target Hive source where you upload the result file. |
hdfs_source |
hdfs_source |
Select the File Storage HDFS resource of your OU from the dropdown list. |
Specify the target HDFS source where you upload the result file. |
ouid |
string |
Enter your OU ID, which you can get by hovering over the OU name on the top navigation bar. |
Specify your OU ID. |
Step 3. Configuring Operators¶
To calculate the power loss of offshore wind turbines, you need to add the following operators.
Operator |
Description |
|---|---|
PythonEx |
Calculate the power loss of offshore wind turbines. |
Condition 1 |
Decide whether to upload results to Hive. |
Condition 2 |
Decide whether to upload results to HDFS. |
PythonCode |
Upload results to Hive. |
Hive |
Create a Hive table to store the results. |
HDFS Uploader |
Upload results to HDFS in .csv format. |
Configuring a PythonEx Operator to Calculate Power Loss¶
On the power-loss pipeline canvas, drag a PythonEx operator from the left operator list.
Select the operator and configure the following operator parameters in the Input Parameter section on the right panel.
Parameter
Reference/Declaration
Description
workspace
Declaration
Select the Notebook instance folder you created in Unit3. Preparing Codes.
entrypoint
Declaration
Select power-loss.py.
requirements
Declaration
Select requirement.txt.
Select Add Parameter in the Input Parameter section for 3 times to add 3 input parameters and configure the following information.
Name
Type
Reference/Declaration
Value
Description
sur_wtg_dts
string
Reference
sur_wtg_dts
Specify the sample dataset for surrounding turbine information.
dwntm_recds_dts
string
Reference
dwntm_recds_dts
Specify the sample dataset for turbine shutdown records.
wtg_10m_dts
string
Reference
wtg_10m_dts
Specify the sample dataset for turbine generated power.
Select Add Parameter in the Output Parameter section, add a new output parameter with
result_fileas the parameter name andfileas the type.
Configuring a Condition Operator to Store Results to Hive¶
On the power-loss pipeline canvas, drag a Condition operator from the left operator list.
Connect the output port of the PythonEx operator to the input port of this Condition operator.
Select the operator and configure the following expression for the Condition operator on the right panel.
Reference | hive_source | != | Declaration | <null>
After configuring this Condition operator as above, you need to double-select the operator to open its sub-canvas and add another Condition operator to upload results to HDFS.
Configuring a Condition Operator to Upload Results to HDFS¶
On the sub-canvas of the Condition operator you created above, drag a Condition operator from the left operator list.
Select the operator and configure the following expression for the Condition operator on the right panel.
Reference | hive_source | != | Declaration | <null>
After configuring this Condition operator as above, you need to double-select the operator to open its sub-canvas and add the following operators:
A PythonCode operator to upload results to Hive
A Hive operator to create a Hive table
A HDFS Uploader operator to upload the results to HDFS in a .csv file
Configuring a PythonCode Operator to Upload Results to Hive¶
On the sub-canvas of the second Condition operator you created above, drag a PythonCode operator from the left operator list.
Enter the following codes for the code parameter on the right panel.
import json import argparse from pathlib import Path # Define an ArgumentParser parser = argparse.ArgumentParser() parser.add_argument("--ouid", type=str, required=True) parser.add_argument("--sql_statements", type=str, required=True) parser.add_argument("--hdfs_dest", type=str, required=True) args = parser.parse_args() target_sqls = [f"""create external table if not exists `power_loss`( `site_id` string comment 'Site', `device_id` string comment 'Turbine', `iec_group_id` string comment 'Status ID', `iec_level4_description` string comment 'Status Description', `start_time` timestamp comment 'Start Time', `end_time` timestamp comment 'End Time', `sur_avb_wtg1` string comment 'Surrounding Turbine 1', `sur_avb_wtg2` string comment 'Surrounding Turbine 2', `power-loss1` string comment 'Power Loss 1 (kWh)', `power-loss2` string comment 'Power Loss 2(kWh)', `power-loss-avg` string comment 'Average Power Loss (kWh)' ) COMMENT 'Power Loss Table' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim'=',', 'serialization.format'=',') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/user/data_{args.ouid}/hbjtdemo/power-loss' TBLPROPERTIES ( 'skip.header.line.count'='1', 'timestamp.formats' = 'yyyy-MM-dd HH:mm:ss')"""] Path(args.sql_statements).parent.mkdir(parents=True, exist_ok=True) with open(args.sql_statements, 'w') as f: json.dump(target_sqls, f) Path(args.hdfs_dest).parent.mkdir(parents=True, exist_ok=True) with open(args.hdfs_dest, 'w') as f: f.write(f"/user/data_{args.ouid}/hbjtdemo/power-loss")
Select Add Parameter in the Input Parameter section add an input parameter and configure the following information.
Name
Type
Reference/Declaration
Value
Description
ouid
string
Reference
ouid
Specify the ID of the current OU.
Select Add Parameter in the Output Parameter section twice to add 2 output parameters and configure the following information.
Name
Type
sql_statement
list
hdfs_dest
string
Configuring a Hive Operator to Create a Hive Table¶
On the sub-canvas of the second Condition operator you created above, drag a Hive operator from the left operator list.
Connect the output port of the PythonCode operator to the input port of this Hive operator.
Select this Hive operator and configure the following operator parameters in the Input Parameter section on the right panel.
Parameter
Reference/Declaration
Description
data_source_name
Reference
Select hive_source.
sqls
Reference
Select pythonCode.sql_statement.
Configuring an HDFS Uploader Operator to Upload Results¶
On the sub-canvas of the second Condition operator you created above, drag an HDFS Uploader operator from the left operator list.
Connect the output ports of both the PythonCode operator and the Hive operator to the input port of this HDFS Uploader operator.
Select this Hive operator and configure the following information in the Input Parameter section on the right panel.
Parameter
Reference/Declaration
Description
data_source_name
Reference
Select hdfs_source.
file
Reference
Select PythonEX.result_file.
dest
Declaration
Select PythonCode.hdfs_dest.
Select Add Parameter in the Input Parameter section to add an input parameter and configure the following information.
Name
Type
Reference/Declaration
Value
Description
overwrite
boolean
Declaration
true
Overwrite if the table with the same name exists.
Step 4. Running the Pipeline¶
On the sub-canvas of the second Condition operator you created above, select Run
on the top toolbar.Select OK to run the pipeline in the pop-up window.
Besides running the power-loss pipeline by Run , you can also schedule the pipeline to run it on a schedule automatically. For more information, see Configure Schedules for Pipelines.
(Optional) Step 5. Viewing Pipeline Running Status¶
When the pipeline is running, you can view the pipeline running status by the following steps:
On the AI Pipelines > Custom Pipeline tab, select the Run Instance of the power-loss pipeline.
Select the instance name on the instance list.
View the running status of the power-loss pipeline on the following tabs:
On the DAG Graph tab, you can view the running results of running instance, including the running progress, input and output parameters, current running logs, and Pod information of operators.
On the Detail tab, you can view the details, running parameters, and advanced configuration of the running instance.
On the Gantt tab, you can view the running status distribution diagram of each operator and the running progress.