Unit 2. Designing a Pipeline¶
The EAP MI Pipelines provides the logic, file, model and other types of operators to meet the business needs of a variety of model training processes and scenarios. This unit describes how to use operators to organize pipelines and develop wind farm power generation prediction models.
Prerequisites¶
Before orchestrating a pipeline, you can create a new experiment in the MI Pipelines by following these steps:
Log in to the EnOS Management Console, and select Enterprise Analytics Platform > Machine Intelligence Studio > MI Pipelines from the left navigation bar to open the Experiment List homepage.
Click New Experiment and enter the name (kmmkdsdemo) and description of the experiment.
Click OK to create the experiment, open the Pipeline Designer page of the experiment for designing and developing the pipeline.
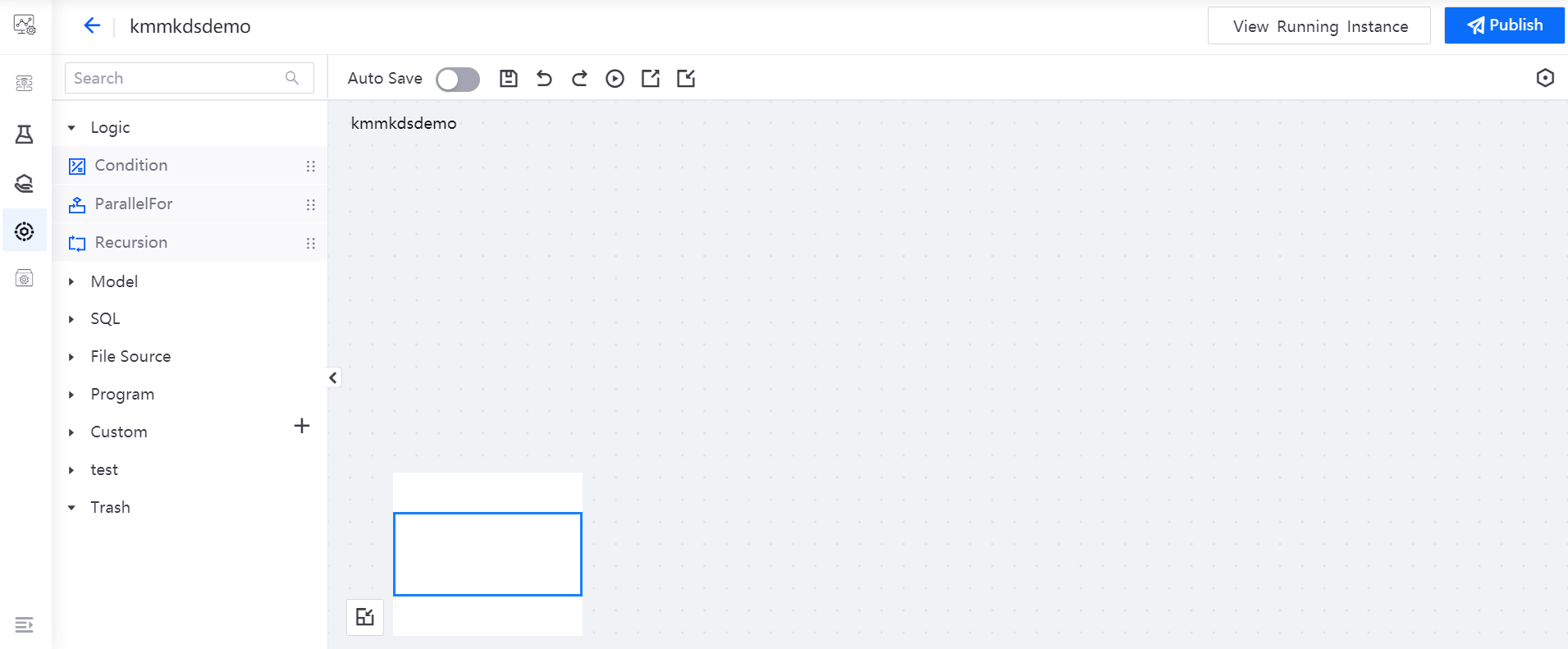
Designing Pipelines¶
The following operators are needed to orchestrate the pipeline in this tutorial:
Hive operator: query the Hive to get the list of sites to be trained (partition or field query), and get the keytab and kerberos profiles required by the Hive operator.
Git Directory operator: get the file
transform1.pyfrom the Git directory and use it as input of Python operatorPython operator: format the input file and take it as the input of ParallelFor operator
ParallelFor operator: implement the loop processing for each site
Drag the operators to the editing canvas, and the pipeline after orchestration is shown in the figure below:

The configuration instructions for each operator orchestrated in the pipeline are given as follows:
Hive Operator¶
Name: Hive
Description: query the Hive to get the list of sites to be trained, and get the keytab and krb5 profiles
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
data_source_name |
String |
Declaration |
Name of the registered Hive data source |
sqls |
List |
Declaration |
[“set tez.am.resource.memory.mb=1024”,”select distinct lower(masterid) as masterid from kmmlds1”] |
queue |
String |
Declaration |
root.eaptest01 (Name of the big data queue applied for through resource management) |
Output parameters
Parameter Name |
Value |
|---|---|
resultset |
File |
An sample of operator configuration is given as follows:

Git Directory Operator¶
Name: Git Directory for Transform1
Description: pull the Python code file transform1.py from the Git directory
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
data_source_name |
String |
Declaration |
Name of the registered Git data source |
branch |
String |
Declaration |
master |
project |
String |
Declaration |
workspace1 |
paths |
List |
Declaration |
[“workspace1/kmmlds/transform1.py”] |
Output parameters
Parameter Name |
Value |
|---|---|
workspace |
directory |
paths |
list |
An sample of operator configuration is given as follows:

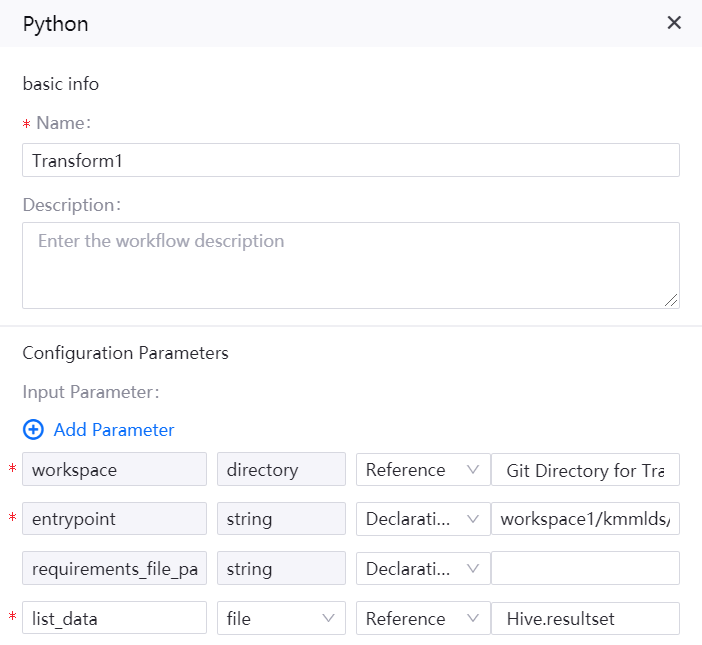
Python Operator¶
Name: Transform1
Description: format the input file and take it as the input of ParallelFor operator. The query output format of the Hive operator is [[], [["abcde0001"], ["cgnwf0046"]]]. It cannot be used directly by the ParallelFor operator. Before that, it needs to be converted through the Python operator, and the converted format is ["abcde0001", "cgnwf0046"].
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
workspace |
Directory |
Reference |
Git Directory for Transform1.workspace |
entrypoint |
String |
Declaration |
workspace1/kmmlds/transform1.py |
requirements_file_path |
String |
Declaration |
|
list_data |
File |
Reference |
Hive.resultset |
Output parameters
Parameter Name |
Value |
|---|---|
output_list |
list |
An sample of operator configuration is given as follows:
ParallelFor Operator¶
Name: Loop for masterid
Description: orchestrate the pipeline in the sub-canvas to process each site
Input parameters
Parameter Name |
Operation Type |
Value |
|---|---|---|
Transform1.output_list |
Reference |
item |
An sample of operator configuration is given as follows:
